ml11_xgb_iris
xgboost
import numpy as np
from sklearn.svm import SVC, LinearSVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, KFold
from sklearn.model_selection import cross_val_score, cross_val_predict
from sklearn.preprocessing import MinMaxScaler, StandardScaler
from sklearn.preprocessing import MaxAbsScaler, RobustScaler
#1. 데이터
datasets = load_iris()
x = datasets['data']
y = datasets.target
x_train, x_test, y_train, y_test =train_test_split(x,y,train_size=0.8, shuffle=True, random_state=42) # train사이즈는 kfold가 발리데이션이ㄴ;까 포함한 0.8
#kfold train,test 셋 나눌 때 아무데나 넣어도 상관없음. kfold 선언이라서
n_splits = 5 # 11이면 홀수 단위로 자름 10개가 train, 1개가 test
random_state = 42
kfold = KFold(n_splits=n_splits, shuffle=True, random_state=random_state)
# sclaer 적용
scaler = MinMaxScaler()
scaler.fit(x_train)
x_train = scaler.transform(x_train)
x_test = scaler.transform(x_test)
#2. 모델(conda에서 xgboost 설치)
from xgboost import XGBClassifier
model = XGBClassifier()
#3. 훈련
model.fit(x_train,y_train)
#4. 평가 예측
score = cross_val_score(model,
x_train, y_train,
cv=kfold) #cv: cross validation
print("cross validation acc: ",score)
#cv acc 는 kfold의 n splits 만큼 값이 나옴 . 5여서 [0.91666667 1. 0.91666667 0.83333333 1. ]
y_predict = cross_val_predict(model,
x_test, y_test,
cv=kfold)
print('cv predict : ', y_predict)
#0.2 y_test 만큼 개수 나옴: cv predict : [1 0 2 1 1 0 1 2 1 1 2 0 0 0 0 1 2 1 1 2 0 1 0 2 2 2 2 2 0 0]
acc = accuracy_score(y_test, y_predict)
print('cv predict acc : ', acc)
# cv predict acc : 0.9666666666666667
#SVC 값 : 결과 acc: 0.9733333333333334
#SVC train test split 결과 acc: 0.9777777777777777
#LinearSVC() 결과 acc: 0.9666666666666667
#딥러닝 결과 : 찾아보기,,
#Scaler 적용
#Standard : 0.9333333333333333
#Minmax : 0.9333333333333333
#MaxAbs: 0.9555555555555556
#Robuster: 0.9333333333333333
#decision tree
#scaler: minmax 결과 acc: 0.9555555555555556
#앙상블 scaler: minmax 결과 acc: 0.9555555555555556
#kfold: n 11,3,5 결과 acc: 1.0
#train,test set kfold - cv predict acc : 0.9666666666666667
#xgboost : 0.8666666666666666666666lightgbm - 코드 오류 찾기
import numpy as np
from sklearn.svm import SVC, LinearSVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, KFold
from sklearn.model_selection import cross_val_score, cross_val_predict
from sklearn.preprocessing import MinMaxScaler, StandardScaler
from sklearn.preprocessing import MaxAbsScaler, RobustScaler
#1. 데이터
datasets = load_iris()
x = datasets['data']
y = datasets.target
x_train, x_test, y_train, y_test =train_test_split(x,y,train_size=0.8, shuffle=True, random_state=42) # train사이즈는 kfold가 발리데이션이ㄴ;까 포함한 0.8
#kfold train,test 셋 나눌 때 아무데나 넣어도 상관없음. kfold 선언이라서
n_splits = 5 # 11이면 홀수 단위로 자름 10개가 train, 1개가 test
random_state = 42
kfold = KFold(n_splits=n_splits, shuffle=True, random_state=random_state)
# sclaer 적용
scaler = MinMaxScaler()
scaler.fit(x_train)
x_train = scaler.transform(x_train)
x_test = scaler.transform(x_test)
#2. 모델(conda에서 xgboost 설치)
from lightgbm import LGBMClassifier
model = LGBMClassifier()
#3. 훈련
model.fit(x_train,y_train)
#4. 평가 예측
score = cross_val_score(model,
x_train, y_train,
cv=kfold) #cv: cross validation
print("cross validation acc: ",score)
#cv acc 는 kfold의 n splits 만큼 값이 나옴 . 5여서 [0.91666667 1. 0.91666667 0.83333333 1. ]
y_predict = cross_val_predict(model,
x_test, y_test,
cv=kfold)
print('cv predict : ', y_predict)
#0.2 y_test 만큼 개수 나옴: cv predict : [1 0 2 1 1 0 1 2 1 1 2 0 0 0 0 1 2 1 1 2 0 1 0 2 2 2 2 2 0 0]
acc = accuracy_score(y_test, y_predict)
print('cv predict acc : ', acc)
# cv predict acc : 0.9666666666666667
#SVC 값 : 결과 acc: 0.9733333333333334
#SVC train test split 결과 acc: 0.9777777777777777
#LinearSVC() 결과 acc: 0.9666666666666667
#딥러닝 결과 : 찾아보기,,
#Scaler 적용
#Standard : 0.9333333333333333
#Minmax : 0.9333333333333333
#MaxAbs: 0.9555555555555556
#Robuster: 0.9333333333333333
#decision tree
#scaler: minmax 결과 acc: 0.9555555555555556
#앙상블 scaler: minmax 결과 acc: 0.9555555555555556
#kfold: n 11,3,5 결과 acc: 1.0
#train,test set kfold - cv predict acc : 0.9666666666666667
#xgboost : 0.8666666666666666666666
#lgbm : 0.2catboost
#feature importance
import numpy as np
from sklearn.tree import DecisionTreeRegressor
from sklearn.svm import SVC, LinearSVC
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import r2_score
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split, KFold
from sklearn.model_selection import cross_val_score, cross_val_predict
from sklearn.preprocessing import MinMaxScaler, StandardScaler
from sklearn.preprocessing import MaxAbsScaler, RobustScaler
#1. 데이터
datasets = fetch_california_housing()
x = datasets['data']
y = datasets.target
x_train, x_test, y_train, y_test =train_test_split(x,y,train_size=0.8, shuffle=True, random_state=42) # train사이즈는 kfold가 발리데이션이ㄴ;까 포함한 0.8
#kfold train,test 셋 나눌 때 아무데나 넣어도 상관없음. kfold 선언이라서
n_splits = 5 # 11이면 홀수 단위로 자름 10개가 train, 1개가 test
random_state = 42
kfold = KFold(n_splits=n_splits, shuffle=True, random_state=random_state)
# sclaer 적용
scaler = MinMaxScaler()
scaler.fit(x_train)
x_train = scaler.transform(x_train)
x_test = scaler.transform(x_test)
#2. 모델(conda에서 catboost 설치)
from catboost import CatBoostRegressor
model = CatBoostRegressor()
#3. 훈련
model.fit(x_train,y_train)
#4. 평가 예측
score = cross_val_score(model,
x_train, y_train,
cv=kfold) #cv: cross validation
y_predict = cross_val_predict(model,
x_test, y_test,
cv=kfold)
r2 = r2_score(y_test, y_predict)
print('r2 :', r2)
#catboost: r2 : 0.8148568252525309catboost iris
import numpy as np
from sklearn.svm import SVC, LinearSVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, KFold
from sklearn.model_selection import cross_val_score, cross_val_predict
from sklearn.preprocessing import MinMaxScaler, StandardScaler
from sklearn.preprocessing import MaxAbsScaler, RobustScaler
#1. 데이터
datasets = load_iris()
x = datasets['data']
y = datasets.target
x_train, x_test, y_train, y_test =train_test_split(x,y,train_size=0.8, shuffle=True, random_state=42) # train사이즈는 kfold가 발리데이션이ㄴ;까 포함한 0.8
#kfold train,test 셋 나눌 때 아무데나 넣어도 상관없음. kfold 선언이라서
n_splits = 5 # 11이면 홀수 단위로 자름 10개가 train, 1개가 test
random_state = 42
kfold = KFold(n_splits=n_splits, shuffle=True, random_state=random_state)
# sclaer 적용
scaler = MinMaxScaler()
scaler.fit(x_train)
x_train = scaler.transform(x_train)
x_test = scaler.transform(x_test)
#2. 모델(conda에서 catboost 설치)
from catboost import CatBoostClassifier
model = CatBoostClassifier()
#3. 훈련
model.fit(x_train,y_train)
#4. 평가 예측
score = cross_val_score(model,
x_train, y_train,
cv=kfold) #cv: cross validation
print("cross validation acc: ",score)
#cv acc 는 kfold의 n splits 만큼 값이 나옴 . 5여서 [0.91666667 1. 0.91666667 0.83333333 1. ]
y_predict = cross_val_predict(model,
x_test, y_test,
cv=kfold)
print('cv predict : ', y_predict)
#0.2 y_test 만큼 개수 나옴: cv predict : [1 0 2 1 1 0 1 2 1 1 2 0 0 0 0 1 2 1 1 2 0 1 0 2 2 2 2 2 0 0]
acc = accuracy_score(y_test, y_predict)
print('cv predict acc : ', acc)
# cv predict acc : 0.9666666666666667
#SVC 값 : 결과 acc: 0.9733333333333334
#SVC train test split 결과 acc: 0.9777777777777777
#LinearSVC() 결과 acc: 0.9666666666666667
#딥러닝 결과 : 찾아보기,,
#Scaler 적용
#Standard : 0.9333333333333333
#Minmax : 0.9333333333333333
#MaxAbs: 0.9555555555555556
#Robuster: 0.9333333333333333
#decision tree
#scaler: minmax 결과 acc: 0.9555555555555556
#앙상블 scaler: minmax 결과 acc: 0.9555555555555556
#kfold: n 11,3,5 결과 acc: 1.0
#train,test set kfold - cv predict acc : 0.9666666666666667
#xgboost : 0.8666666666666666666666
#lgbm : 0.2
#catboost: cv predict acc : 0.9666666666666667xgb는 plot 띄우는거 따로 있음
#feature importance
import numpy as np
from sklearn.tree import DecisionTreeRegressor
from sklearn.svm import SVC, LinearSVC
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import r2_score
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split, KFold
from sklearn.model_selection import cross_val_score, cross_val_predict
from sklearn.preprocessing import MinMaxScaler, StandardScaler
from sklearn.preprocessing import MaxAbsScaler, RobustScaler
#1. 데이터
datasets = fetch_california_housing()
x = datasets['data']
y = datasets.target
x_train, x_test, y_train, y_test =train_test_split(x,y,train_size=0.8, shuffle=True, random_state=42) # train사이즈는 kfold가 발리데이션이ㄴ;까 포함한 0.8
#kfold train,test 셋 나눌 때 아무데나 넣어도 상관없음. kfold 선언이라서
n_splits = 5 # 11이면 홀수 단위로 자름 10개가 train, 1개가 test
random_state = 42
kfold = KFold(n_splits=n_splits, shuffle=True, random_state=random_state)
# sclaer 적용
scaler = MinMaxScaler()
scaler.fit(x_train)
x_train = scaler.transform(x_train)
x_test = scaler.transform(x_test)
#2. 모델(conda에서 xgboost 설치)
from xgboost import XGBRegressor
model = XGBRegressor()
#3. 훈련
model.fit(x_train,y_train)
#4. 평가 예측
score = cross_val_score(model,
x_train, y_train,
cv=kfold) #cv: cross validation
y_predict = cross_val_predict(model,
x_test, y_test,
cv=kfold)
r2 = r2_score(y_test, y_predict)
print('r2 :', r2)
#catboost: r2 : 0.8148568252525309
#xgb: r2 : 0.7784779387669546
#lgbm: r2 : 0.7959873842146158
#시각화
import matplotlib.pyplot as plt
from xgboost.plotting import plot_importance
plot_importance(model)
plt.show()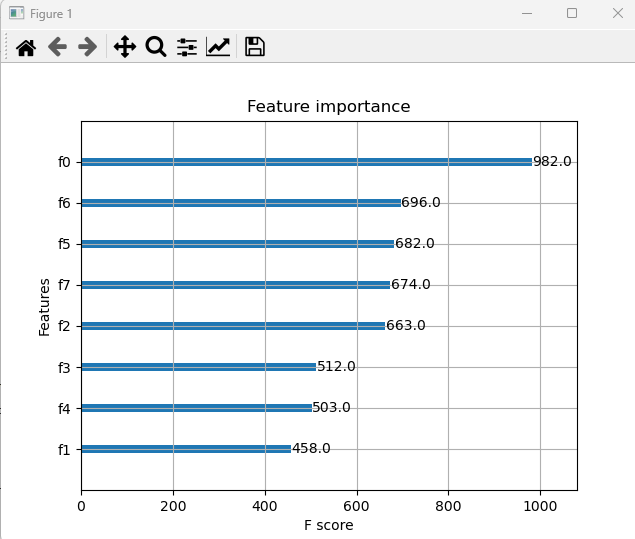
'[네이버클라우드] 클라우드 기반의 개발자 과정 7기 > AI' 카테고리의 다른 글
| 머신러닝 2 /GridSearch, outlier, Bagging, Voting (0) | 2023.05.16 |
|---|---|
| [수업자료] ml2 오늘의 코드 -gridsearch, random, bagging (0) | 2023.05.16 |
| 머신러닝 1 / feature importance (0) | 2023.05.16 |
| 머신러닝 1 -model, scaling (0) | 2023.05.15 |
| heatmap NaN, label Encoding - 팀플 쓰기 (2) | 2023.05.12 |