퍼셉트론의 과제 : XOR
(퍼셉트론으로 AND, OR 해결 가능. 하지만 ,, XOR은 못 함. 인공지능의 winter, ,,, )
AND : 0이 하나라도 있으면 0
OR: 1이 하나라도 있으면 1
XOR
#1. 데이터 xor: 다르면 1
x_data = [[0,0],[0,1],[1,0],[1,1]]
y_data = [0,1,1,0]
#2. 모델
model = Perceptron()
모델의 score : 0.5
# [[0, 0], [0, 1], [1, 0], [1, 1]] 의 예측결과 : [0 0 0 0]
# acc : 0.5MODEL
SVM 모델 (suport vecter machine)
- 서포트 벡터 머신은 여백(margin)을 최대화하는 지도 학습 알고리즘
- 여백은 주어진 데이터가 오류를 발생키지 않고 움직일 수 있는 최대공간
- 분류를 위한 서포트 벡터 머신: SVC
- 회귀를 위한 서포트 벡터 머신: SVR
- 딥러닝의 MLP(Multi Layer Perceptron) 와 비슷한 값을 내지만 때에 따라 효율이 다름
#1. 데이터 xor: 다르면 1
x_data = [[0,0],[0,1],[1,0],[1,1]]
y_data = [0,1,1,0]
#2. 모델
model = SVC()
#3. 훈련
model.fit(x_data, y_data)
#4. 평가 예측- 생략
모델의 score : 1.0
[[0, 0], [0, 1], [1, 0], [1, 1]] 의 예측결과 : [0 1 1 0]
acc : 1.0분류 모델 cancer SVM 과 tf keras 성능 비교
# [실습] svm 모델과 나의 tf keras 모델 성능비교하기
#1. 데이터
datasets = load_breast_cancer()
train, test set 설정
#2. 모델
model = LinearSVC()
#3. 훈련
model.fit(x_train,y_train)
#4. 평가 예측
SVC 결과 acc: 0.9064327485380117
Linear SVC 결과 acc: 0.9415204678362573
딥러닝: accuracy : 0.9064327485380117
Decision Tree
- 분류와 회귀 문제에 널리 사용하는 모델
- 예/아니오 질문을 이어 나가면서 학습
- DecisionTreeRegressor와 DecisionTreeClassifier
decisiontree_iris
from sklearn.tree import DecisionTreeClassifier
#2. 모델
model = DecisionTreeClassifier()
*************
decision tree
scaler: minmax 결과 acc: 0.9555555555555556decisiontree_iris
from sklearn.tree import DecisionTreeClassifier
#2. 모델
model = DecisionTreeClassifier()
*********************
decision tree
minmax: 0.935672514619883
MaxAbs: 0.9415204678362573
Robuster: 0.9298245614035088decisiontree_cali
from sklearn.tree import DecisionTreeRegressor
#2. 모델
model = DecisionTreeRegressor()
****************************************************
#SVR 결과 acc: -0.01663695941103427
#Linear SVC 결과 acc: -0.055781872981941705
#딥러닝: accuracy 결과 acc: -1.8172916629018916
#decision tree- regressor
#Minmax: 결과 r2 : 0.6252904174582093
#Standard 결과 : 0.610199889411199
Random Forest
여러 개의 결정 트리들을 임의적으로 학습하는 방식의 앙상블 방법
boost 나오기 전에 많이 사용됐었음
Decision Tree보다 값이 좋음
cancer 앙상블
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
#2. 모델
model = RandomForestClassifier()
*********************************************
decision tree
minmax: 결과 acc: 0.935672514619883
MaxAbs: 0.9415204678362573
Robuster: 0.9298245614035088
앙상블
Robuster: 결과 acc: 0.9649122807017544cali 앙상블
from sklearn.ensemble import RandomForestRegressor
#2. 모델
model = RandomForestRegressor()
*********************************************
decision tree
Minmax: 결과 r2 : 0.6252904174582093
Standard 결과 : 0.610199889411199
앙상블
standard : 0.8134721940607257[Boosting 계열의 모델]
Boosting 이란 약한 분류기를 결합하여 강한 분류기를 만드는 과정
Adaptive Boosting (AdaBoost) : 다수결을 통한 정답 분류 및 오답에 가중치 부여
Gradient Boosting Mode (GBM) : LightGBM, CatBoost, XGBoost - Gradient Boositng Alogorithm을 구현한 패키지
XGBoost
#2. 모델(conda에서 xgboost 설치)
from xgboost import XGBClassifier
model = XGBClassifier()
xgboost : 0.8666666666666666666666LightGBM
#2. 모델(conda에서 xgboost 설치)
from lightgbm import LGBMClassifier
model = LGBMClassifier()
xgboost : 0.8666666666666666666666
lgbm : 0.2CatBoost
#2. 모델(conda에서 catboost 설치)
from catboost import CatBoostClassifier
model = CatBoostClassifier()
xgboost : 0.8666666666666666666666
lgbm : 0.2
catboost: cv predict acc : 0.9666666666666667
XGBoost plot 띄우는 법 - 보기 어려움
#시각화
import matplotlib.pyplot as plt
from xgboost.plotting import plot_importance
plot_importance(model)
plt.show()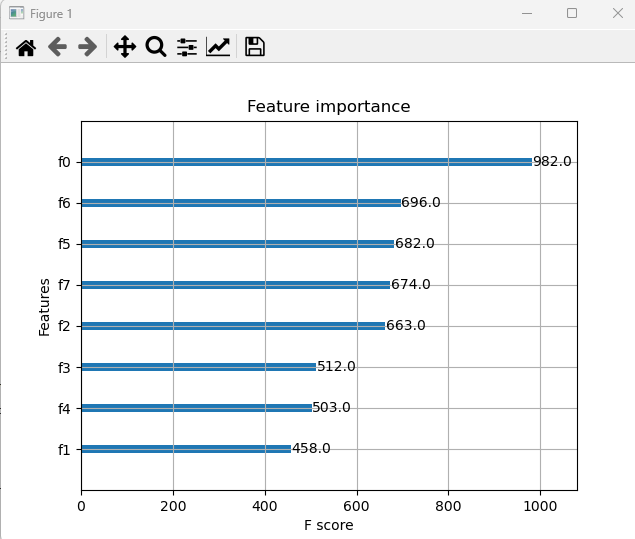
K-Fold
ML 모델에서 가장 보편적으로 사용되는 교차 검증 기법
K개의 데이터 폴드 세트를 만들어서 K번만큼 각 폴드 세트에 학습과 검증 평가를 수행
KFold : 회귀 문제에서의 교차검증
StratifedKFold : 레이블 데이터가 왜곡되었을 경우, 분류에서 교차 검증
cancer K-Fold
#kfold
n_splits = 5
random_state = 42
kfold = KFold(n_splits=n_splits, shuffle=True, random_state=random_state)
sclaer RobustScaler() 적용
#2. 모델
model = RandomForestClassifier()
#3. 훈련
model.fit(x_train,y_train)
********************************************
decision tree
Robuster: 0.9298245614035088
앙상블
Robuster: 결과 acc: 0.9649122807017544
앙상블 + Kfold
acc : 0.9532163742690059cali K-Fold
from sklearn.model_selection import train_test_split, KFold
#kfold
n_splits = 5
random_state =42
kfold = KFold(n_splits=n_splits, shuffle=True, random_state=random_state)
********************************
decision tree- regressor
Minmax: 결과 r2 : 0.6252904174582093
Standard 결과 : 0.610199889411199
앙상블
standard : 0.8134721940607257
앙상블 + kfold
r2 score : 0.7736576724548081stratifiedKFold_iris
from sklearn.model_selection import StratifiedGroupKFold
#1. 데이터
datasets = load_iris()
#StratifiedGroupKFold
n_splits = 5 # 11이면 홀수 단위로 자름 10개가 train, 1개가 test
random_state = 42
kfold = StratifiedGroupKFold(n_splits=n_splits, shuffle=True, random_state=random_state)
# sclaer 적용 scaler = MinMaxScaler()
#2. 모델
model = RandomForestClassifier()
#3. 훈련
model.fit(x,y)
#4. 평가 예측
result = model.score(x,y)
print('결과 acc: ', result)
*************************************************
#decision tree
#scaler: minmax 결과 acc: 0.9555555555555556
#앙상블
#scaler: minmax 결과 acc: 0.9555555555555556
#kfold: n 11,3,5 결과 acc: 1.0
#strait :결과 acc: 1.0스케일링 (Scaling)
Normalization(정규화) : 데이터를 0과 1사이의 범위로 조정, 상대적인 크기를 유지하면서 모델이 더 잘 학습하게 도움
Standardization(표준화) : 평균이 0, 표준편차가 1로 변환, 데이터의 분포를 조정하여 이상치에 대해 덜 민감하게 만듬
MinMaxScaler(), 0과 1사이로 스케일링, 이상치에 민감하며, 회귀에 유용
StandardScaler(), 평균을 0, 분산을 1로 스케일링, 이상치에 민감하며, 분류에 유용함
MaxAbsScaler(), 특성의 절대값이 0과 1 사이가 되도록 스케일링. 모든 값은 -1과 1사이로 표현되며 양수일 경우 minmax와 동일
RobustScaler(), 평균과 분산 대신 중간 값과 사분위 값을 사용, 이상치 영향을 최소화할 수 있음
*train은 fit과 transform, test는 transform scaler
* 스케일러 적용 전에도 예측값이 좋았던 건 스케일러 적용했을 때 값이 나빠질 수도 있다.
아래 Iris와 wine 데이터 비교
Iris scaler 4개 적용
from sklearn.preprocessing import MinMaxScaler, StandardScaler
from sklearn.preprocessing import MaxAbsScaler, RobustScaler
#1. 데이터
datasets = load_iris()
x_train, x_test, y_train, y_test = train_test_split(x,y,train_size=0.7, random_state=100)
# sclaer 적용
scaler = StandardScaler()
x_train = scaler.fit_transform(x_train)
x_test = scaler.transform(x_test)
#2. 모델
model = LinearSVC()
#3. 훈련
model.fit(x_train,y_train)
#4. 평가 예측
result = model.score(x_test,y_test)
print('결과 acc: ', result)
**************************************************
#LinearSVC() 결과 acc: 0.9666666666666667
***************************************************
#Scaler 적용
#Standard : 0.9333333333333333
#Minmax : 0.9333333333333333
#MaxAbs: 0.9555555555555556
#Robuster: 0.9333333333333333
cancer scaler 4개 적용
from sklearn.preprocessing import MinMaxScaler, StandardScaler
from sklearn.preprocessing import MaxAbsScaler, RobustScaler
#1. 데이터
datasets = load_breast_cancer()
x_train, x_test, y_train, y_test = train_test_split(x,y,train_size=0.7, random_state=100)
# sclaer 적용
scaler = MaxAbsScaler()
x_train = scaler.fit_transform(x_train)
x_test = scaler.transform(x_test)
#2. 모델
model = LinearSVC()
#3. 훈련
model.fit(x_train,y_train)
#4. 평가 예측
result = model.score(x_test,y_test)
print('결과 acc: ', result)
***************************************************
#Linear SVC 결과 acc: 0.9415204678362573
#딥러닝: accuracy : 0.9064327485380117
Scaler 적용
Standard : 0.9473684210526315
Minmax : 0.9649122807017544
MaxAbs: 0.9649122807017544
Robuster: 0.9532163742690059
'[네이버클라우드] 클라우드 기반의 개발자 과정 7기 > AI' 카테고리의 다른 글
| [수업자료] ml1 오늘의 코드3 (0) | 2023.05.16 |
|---|---|
| 머신러닝 1 / feature importance (0) | 2023.05.16 |
| heatmap NaN, label Encoding - 팀플 쓰기 (2) | 2023.05.12 |
| [5-1] 개념정리 - 자연어처리(NLP) 기초 (0) | 2023.05.12 |
| [4-3] 판다스... 찍 (3) | 2023.05.11 |