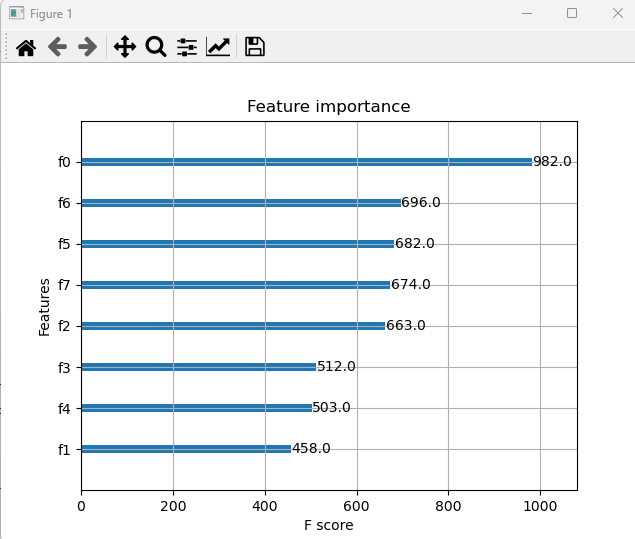
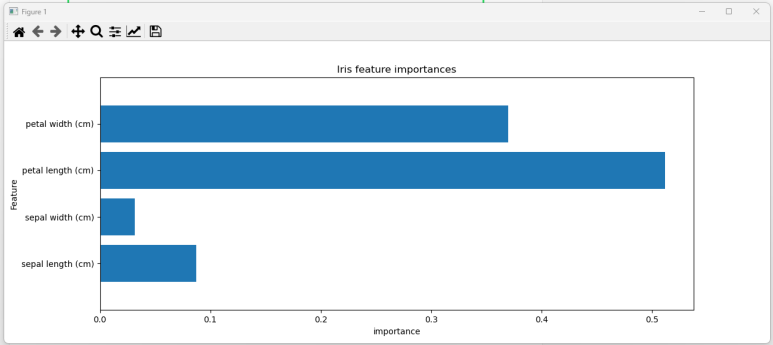
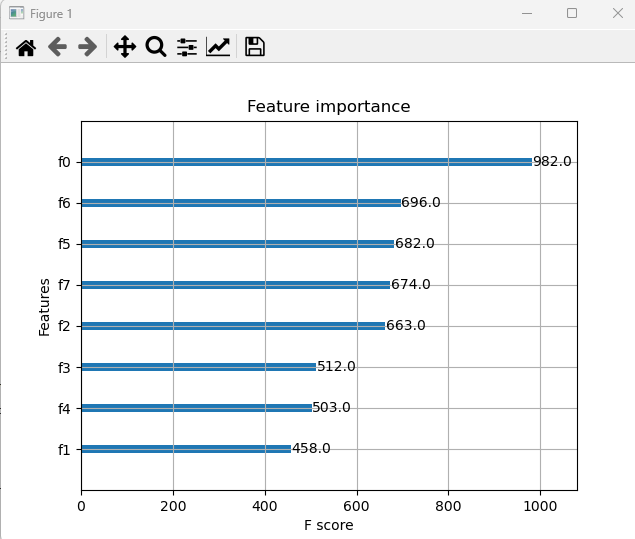
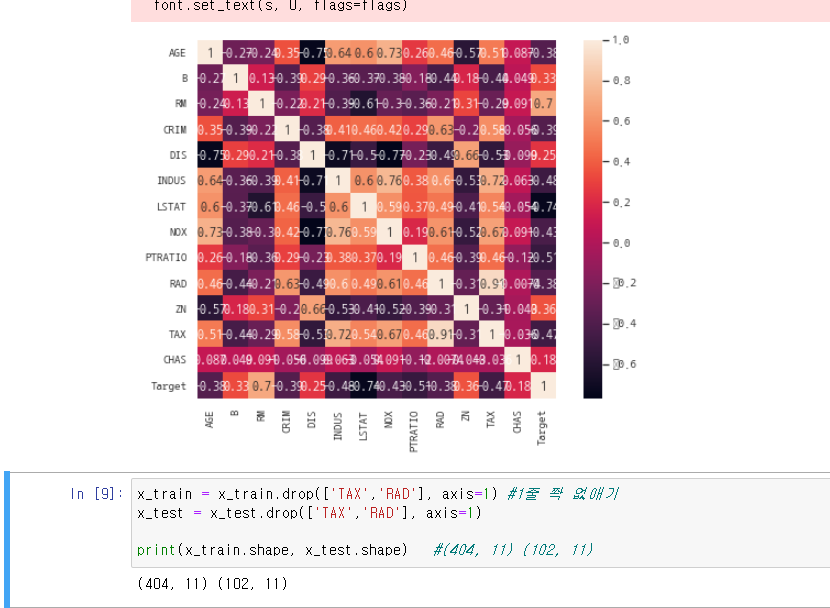
ml11_xgb_iris xgboost import numpy as np from sklearn.svm import SVC, LinearSVC from sklearn.tree import DecisionTreeClassifier from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split, KFold from sklearn.model_selection import cross_val_score, cross_val_predict from ..