validation - 트레인셋을 검증, 트레인셋에 소속된 개념. 테스트 전에 모델이 최적 검증
6:2:2
validation이나 모델 or 가충지 저장하던지 멀 하던지 다 fit에 넣기
#라이브러리 구성, 정리
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
#1. 데이터
x = np.array([1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20])
y = np.array([1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20])
# x = np.array(range(1,21))
# y = np.array(range(1,21))
# print(x.shape)
# print(y.shape)
# print(x)
x_train = np.array([1,2,3,4,5,6,7,8,9,10,11,12])
y_train = np.array([1,2,3,4,5,6,7,8,9,10,11,12])
x_test = np.array([17,18,19,20])
y_test = np.array([17,18,19,20])
x_val = np.array([13,14,15,16])
y_val = np.array([13,14,15,16])
#2.모델 구성
model = Sequential()
model.add(Dense(14, input_dim=1))
model.add(Dense(50))
model.add(Dense(1))
#3.컴파일, 훈련
model.compile(loss='mse', optimizer='adam')
model.fit(x_train, y_train, epochs=100, batch_size=1,
validation_data=[x_val, y_val])
#4. 평가, 예측
loss = model.evaluate(x_test, y_test)
print('loss는', loss)
result = model.predict([21])
print('21의 예측값 : ', result)
#loss는 1.6003641576389782e-05
# 21의 예측값 : [[20.994898]]
# Epoch 95/100
# 12/12 [==============================] - 0s 3ms/step - loss: 1.0737e-05 - val_loss: 1.6065e-05
# val_loss: 1.6065e-05 라는게 생김김
val_loss의 모니터는 히스토리
fit에서 validation_data를 설정하면
val_loss값이 자동으로 history에 저장된다.
#라이브러리 구성, 정리
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
#1. 데이터
x = np.array([1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20])
y = np.array([1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20])
# x = np.array(range(1,21))
# y = np.array(range(1,21))
# print(x.shape)
# print(y.shape)
# print(x)
x_train = np.array([1,2,3,4,5,6,7,8,9,10,11,12])
y_train = np.array([1,2,3,4,5,6,7,8,9,10,11,12])
x_test = np.array([17,18,19,20])
y_test = np.array([17,18,19,20])
x_val = np.array([13,14,15,16])
y_val = np.array([13,14,15,16])
#2.모델 구성
model = Sequential()
model.add(Dense(14, input_dim=1))
model.add(Dense(50))
model.add(Dense(1))
#3.컴파일, 훈련
model.compile(loss='mse', optimizer='adam')
hist = model.fit(x_train, y_train, epochs=100, batch_size=1,
validation_data=[x_val, y_val]) #val 넣으면 성능이 좋아질수도 있고 나빠질 수도 있음
#4. 평가, 예측
loss = model.evaluate(x_test, y_test)
print('loss는', loss)
result = model.predict([21])
print('21의 예측값 : ', result)
##history_val_loss 출력
print('=======================================')
print(hist)
print(hist.history)
print('=======================================')
print(hist.history['val_loss'])
## loss와 val_loss 시각화
import matplotlib.pyplot as plt
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True' # 동일한 라이브러리 충돌시 여러 프로세스에서 로드되는 것을 허용
# from matplotlib import font_manager, rc
# font_path = 'C:/Windows\\Fonts\ttf파일명'
# font = font_manager.FontProperties(fname=font_path).get_name()
# rc('font', family=font)
plt.figure(figsize=(9, 6))
plt.plot(hist.history['loss'], marker='.', c='red', label='loss')#plot은 선, scatter는 점 ,marker='. 도트로 표현될거임 v=삼각형, ^ 역삼각형형
plt.plot(hist.history['val_loss'], marker='.', c='blue', label='val_loss')
plt.title('loss & val_loss')
plt.ylabel('loss') #한글 ttf 파일 넣으면 로스
plt.xlabel('epochs') #에폭스
plt.legend()
plt.show()


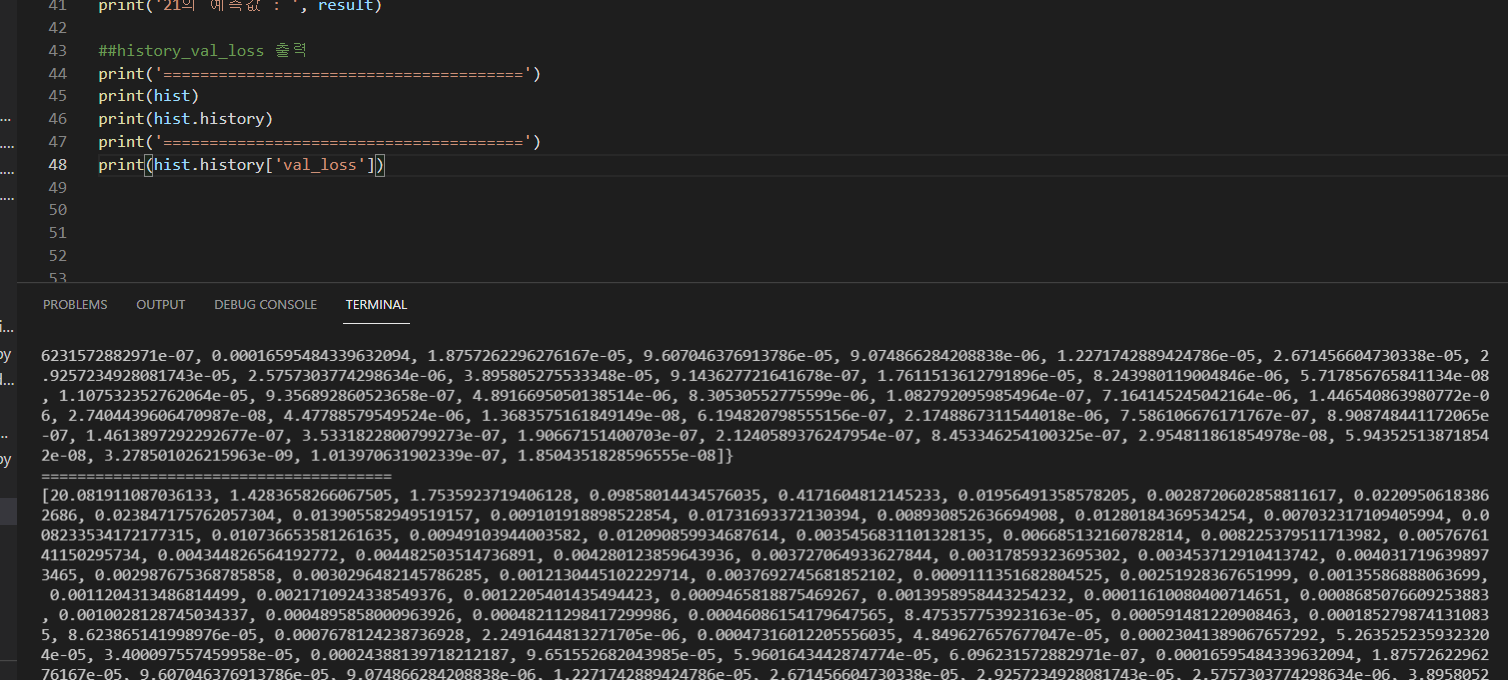
print(hist)는 keras.callbacks.History 객체의 정보를 출력하는데, 이 객체는 모델 학습 동안 발생하는 모든 정보를 담고 있어요. 이 정보들 중에서는 손실(loss) 값과 정확도(accuracy) 값도 있습니다. 그러나 print(hist)로 출력할 경우, 보다 간단하고 요약된 정보만 출력되기 때문에, 전체적인 정보를 확인하려면 hist.history를 출력해보는 것이 좋아요. 이렇게 하면 각 에포크(epoch)마다의 손실값과 정확도 값을 볼 수 있어요.
hist.history['val_loss']는 각 epoch마다의 검증 데이터에 대한 손실 함수 값이 기록된 리스트입니다. 따라서 출력된 값의 개수는 전체 epoch 수와 같습니다. 예를 들어, epoch 수가 100이면 hist.history['val_loss']의 길이는 100이며, 각 epoch에서의 검증 데이터 손실 함수 값이 리스트에 기록됩니다. 이 값을 통해 모델의 성능 변화를 추적할 수 있습니다.
#validation_split & 시각화
일자 그래프 나옴: => 에폭을 길게 할 필요가 없었다 ,,!
#validation_split
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score
from sklearn.datasets import fetch_california_housing
import time
#1. 데이터
datasets = fetch_california_housing()
x = datasets.data #변수, 컬럼, 열
y = datasets.target
print(datasets.feature_names)
print(x.shape) #(20640, 8)
print(y.shape) # (20640,)
x_train, x_test, y_train, y_test = train_test_split(
x,y, train_size=0.6, test_size=0.2, random_state=100, shuffle=True
)
print(x_train.shape) #(14447, 8)
print(y_train.shape) #(14447,)
#2. 모델구성
model=Sequential()
model.add(Dense(100, input_dim=8))
model.add(Dense(100))
model.add(Dense(100))
model.add(Dense(1000))
model.add(Dense(1000))
model.add(Dense(1))
#3. 컴파일,훈련
model.compile(loss='mse', optimizer='adam')
start_time = time.time()
hist = model.fit(x_train, y_train, epochs=500, batch_size=200,
validation_split=0.2) #validation data => 0.2(train 0.6, test 0.2)
end_time = time.time() - start_time
#4. 예측,평가
loss = model.evaluate(x_test, y_test)
y_predict = model.predict(x_test)
r2 = r2_score(y_test, y_predict)
print('r2 스코어: ', r2)
print('걸린시간: ', end_time)
# 시각화
import matplotlib.pyplot as plt
plt.figure(figsize=(9,6))
plt.plot(hist.history['loss'], marker='.',c='orange', label='loss')
plt.plot(hist.history['val_loss'], marker='.', c='blue', label='val_loss')
plt.title('Loss & Val_loss')
plt.ylabel('loss')
plt.xlabel('epochs')
plt.legend()
plt.show()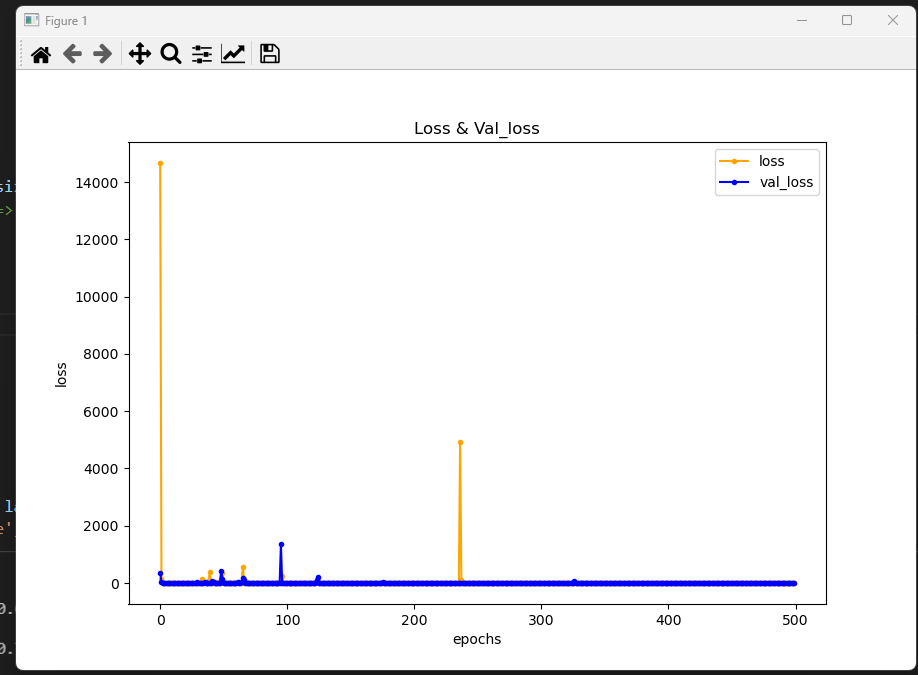
cacer_validation
#이진분류= 회귀 = 캘리포니아
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score, accuracy_score # r2=적합도, ac=정확도
from sklearn.datasets import load_breast_cancer
import time
#1. 데이터
datasets = load_breast_cancer()
print(datasets.DESCR)
print(datasets.feature_names)
# ['mean radius' 'mean texture' 'mean perimeter' 'mean area'
# 'mean smoothness' 'mean compactness' 'mean concavity'
# 'mean concave points' 'mean symmetry' 'mean fractal dimension'
# 'radius error' 'texture error' 'perimeter error' 'area error'
# 'smoothness error' 'compactness error' 'concavity error'
# 'concave points error' 'symmetry error' 'fractal dimension error'
# 'worst radius' 'worst texture' 'worst perimeter' 'worst area'
# 'worst smoothness' 'worst compactness' 'worst concavity'
# 'worst concave points' 'worst symmetry' 'worst fractal dimension']
x = datasets.data
y = datasets.target
print(x.shape, y.shape) #(569, 30) (569,)
x_train, x_test, y_train, y_test = train_test_split(
x, y, train_size=0.6, test_size=0.2, random_state=100, shuffle=True
)
#2. 모델구성
model=Sequential()
model.add(Dense(100, input_dim=30))
model.add(Dense(100))
model.add(Dense(50, activation='relu'))
model.add(Dense(1, activation='sigmoid')) #0이냐 1이냐 찾는 이진분류이기때문에 뉴런 1, 이진분류는 무조건 아웃풋 활성화 함수를: sigmoid
#컴파일, 훈련
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy','mse']) #손실함수는 바이너리 넣어야함, metrics, accuracy 역할할 확인 하기**
start_time= time.time()
hist = model.fit(x_train, y_train, epochs=100, batch_size=200,
validation_split=0.2, verbose=2) #verbose 훈련과정 안 보고 싶을 때 0, 기본보기 1, 막대기 안보기 2
end_time = time.time() - start_time
#평가 예측
# loss =model.evaluate(x_test,y_test)
loss, acc, mse = model.evaluate(x_test, y_test)
y_predict=model.predict(x_test) #소수점 나와서 0인지 1인지 만들어줘야함
#[실습] accurancy score를 출력하라
# 1번 방법 : y_predict 반올림하기
'''
y_predict = np.where(y_predict > 0.5, 1, 0) #0.5보다 크면 1, 아니면 0 할거야
print('loss : ', loss) #loss : [0.34362778067588806, 0.05551309883594513] 2개 나온 이유: metrics: mse 해서 같이 뽑힘힘
print('accuracy : ', acc) #accuracy : 0.9298245614035088
'''
'''
# 2번방법
y_predict = np.round(y_predict)
acc = accuracy_score(y_test, y_predict)
print('loss : ', loss) #loss :[0.18420802056789398, 0.053063519299030304] 2개 나온 이유: metrics: mse 해서 같이 뽑힘힘
print('accuracy : ', acc) #accuracy : 0.9298245614035088
'''
y_predict = np.round(y_predict)
acc = accuracy_score(y_test, y_predict)
print('loss : ', loss) #loss : [0.3225121796131134, 0.9064327478408813, 0.08121472597122192]
print('accuracy : ', acc) #accuracy : 0.9064327485380117
print('걸린 시간: ', end_time) #걸린 시간: 1.084829568862915
#시그모이드랑 바이너리 넣으면 끝, 분류기 때문에 r2scoore가 아니라 accurancy score 체크
#시각화
import matplotlib.pyplot as plt
plt.figure(figsize=(9,6))
plt.plot(hist.history['loss'], marker='.', c='orange', label='loss')
plt.plot(hist.history['val_loss'], marker='.', c='blue', label='val_loss')
plt.title('Loss & Val_loss')
plt.ylabel('loss')
plt.xlabel('epochs')
plt.legend()
plt.show()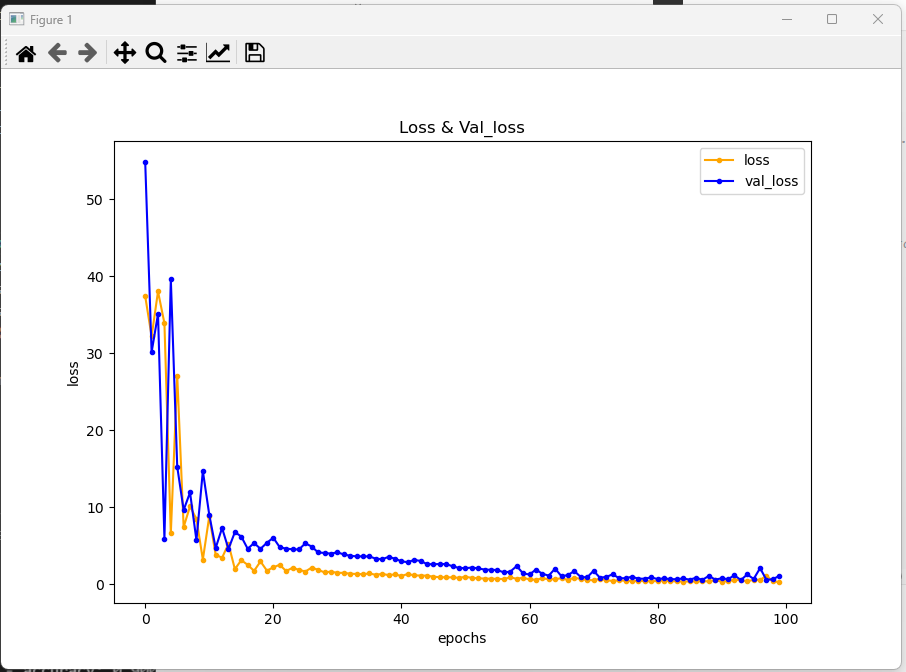
와인 val
#[실습] one hot encoding을 사용하여 분석 (세 가지 방법 중 한 가지 사용)
# validation
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_wine
import time
#1. 데이터
datasets = load_wine()
x = datasets.data
y = datasets.target
from keras.utils import to_categorical
y = to_categorical(y)
x_train, x_test, y_train, y_test = train_test_split(
x,y,train_size=0.6, test_size=0.2, random_state=100, shuffle=True
)
#2. 모델링
model=Sequential()
model.add(Dense(100, input_dim=13))
model.add(Dense(100))
model.add(Dense(50))
model.add(Dense(10))
model.add(Dense(3, activation='softmax'))
#3. 컴파일, 훈련
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics='accuracy')
start_time = time.time()
hist = model.fit(x_train, y_train, epochs=500, batch_size=100, validation_split=0.2)
end_time = time.time() - start_time
print('걸린 시간: ', end_time)
# 예측, 평가
loss, acc = model.evaluate(x_test,y_test)
print('loss: ', loss)
print('acc: ', acc)
#loss: 0.15465861558914185
#acc: 0.9629629850387573
#시각화
import matplotlib.pyplot as plt
plt.figure(figsize=(9,6))
plt.plot(hist.history['loss'], marker='.', c='orange', label='loss')
plt.plot(hist.history['val_loss'], marker='.', c='pink', label='val_loss')
plt.title('Loss & Val_loss')
plt.ylabel('loss')
plt.xlabel('epochs')
plt.legend()
plt.show()

Iris validation
#다중분류 아웃풋 3개,activation='softmax'
#validation
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_iris
import time
#1. 데이터
datasets = load_iris()
print(datasets.DESCR) # 상세정보
print(datasets.feature_names) #['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
x = datasets['data'] # 동일 문법 x = datasets.data
y = datasets.target
print(x.shape, y.shape) #(150, 4) (150,)
x_train, x_test, y_train, y_test = train_test_split(
x, y, train_size=0.6, test_size=0.2, random_state=100, shuffle=True
)
print(x_train.shape, y_train.shape) #(105, 4) (105,)
print(x_test.shape, y_test.shape) #(45, 4) (45,)
print(y_test) #0은 꽃1, 1은 꽃2, 2는 꽃3
#2. 모델링
model=Sequential()
model.add(Dense(100, input_dim=4)) #컬럼 수
model.add(Dense(100))
model.add(Dense(50))
model.add(Dense(50))
model.add(Dense(3, activation='softmax')) #아웃풋 3개
#3. 컴파일, 훈련
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam',metrics=['accuracy'])
#loss='sparse_categorical_crossentropy' 원핫인코딩 안하고 0.1.2 정수로 인코딩 상태에서 수행가능
start_time = time.time()
hist = model.fit(x_train, y_train, epochs=500, batch_size=100, validation_split=0.2)
end_time = time.time() - start_time
print('걸린 시간: ', end_time)
#4. 예측, 평가
loss, acc = model.evaluate(x_test, y_test)
print('loss : ', loss)
print('acc : ', acc)
# accuracy: 1.0000 => 과적합일 가능성이 높음
# loss : 0.020110951736569405
#시각화
import matplotlib.pyplot as plt
plt.figure(figsize=(9,6))
plt.plot(hist.history['loss'], marker='.', c='red', label='loss')
plt.plot(hist.history['val_loss'], marker='.', c='black', label='val_loss')
plt.title('Loss & Val_loss')
plt.ylabel('loss')
plt.xlabel('epochs')
plt.legend()
plt.show()

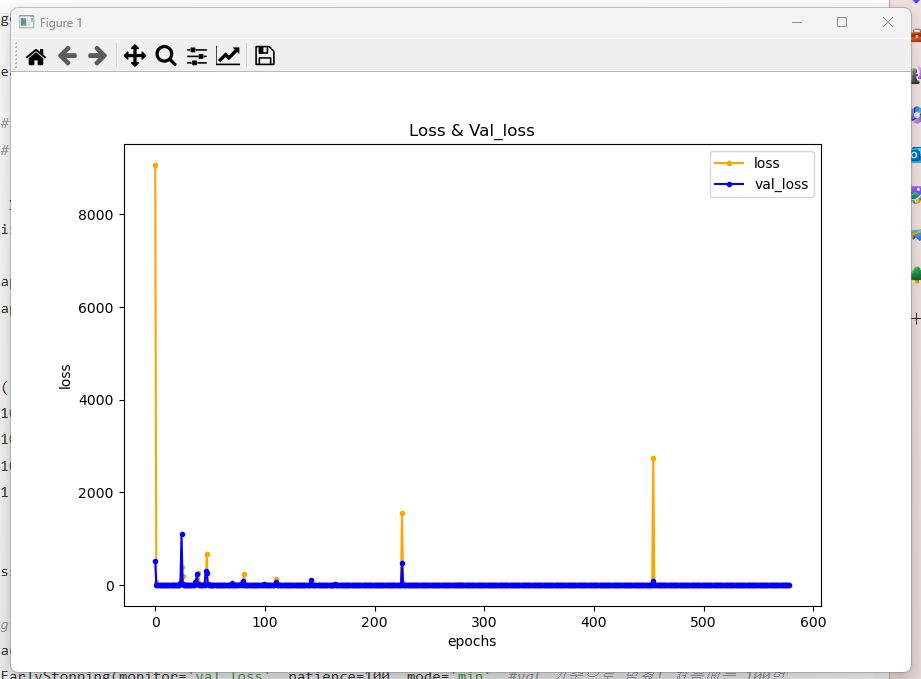
early stopping, 검증로스, 오버피팅(그림 깨끗하게 다시 그리기)
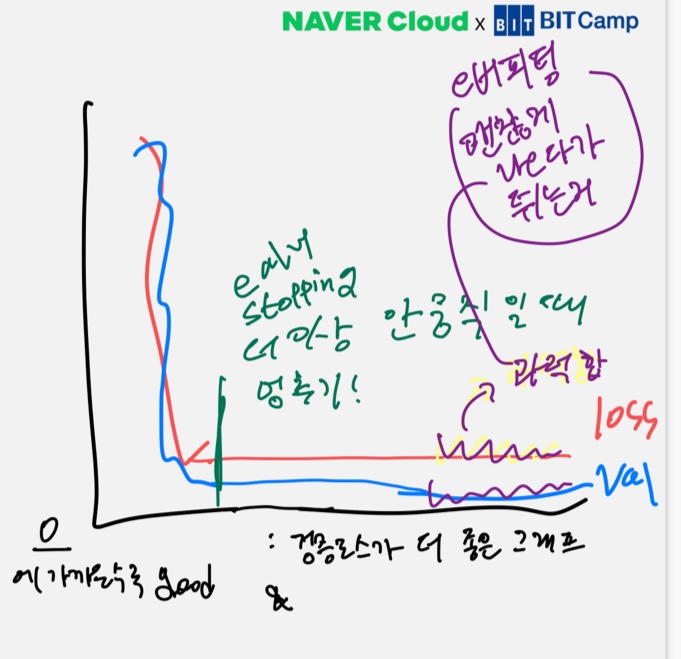
early stopping -california
#validation_split & ealry stopping
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score
from sklearn.datasets import fetch_california_housing
import time
#1. 데이터
datasets = fetch_california_housing()
x = datasets.data #변수, 컬럼, 열
y = datasets.target
print(datasets.feature_names)
print(x.shape) #(20640, 8)
print(y.shape) # (20640,)
x_train, x_test, y_train, y_test = train_test_split(
x,y, train_size=0.6, test_size=0.2, random_state=100, shuffle=True
)
print(x_train.shape) #(14447, 8)
print(y_train.shape) #(14447,)
#2. 모델구성
model=Sequential()
model.add(Dense(100, input_dim=8))
model.add(Dense(100))
model.add(Dense(100))
model.add(Dense(1))
#3. 컴파일,훈련
model.compile(loss='mse', optimizer='adam')
## early stopping
from keras.callbacks import EarlyStopping
earlyStopping = EarlyStopping(monitor='val_loss', patience=100, mode='min', #val 기준으로 멈춰! 처음에는 100번정도,, 작게하면 다음에 튈지도 모름, mode기본값은 auto.
verbose=1, restore_best_weights=True ) #restore~ 기본값: False이므로 가장 좋은 값 나오면 멈출거니? 응 True 체크크
start_time = time.time()
hist = model.fit(x_train, y_train, epochs=5000, batch_size=200,
validation_split=0.2,
callbacks=[earlyStopping],
verbose=1) #1 보겠다
end_time = time.time() - start_time
#4. 예측,평가
loss = model.evaluate(x_test, y_test)
y_predict = model.predict(x_test)
r2 = r2_score(y_test, y_predict)
print('r2 스코어: ', r2)
print('걸린시간: ', end_time)
# 시각화
import matplotlib.pyplot as plt
plt.figure(figsize=(9,6))
plt.plot(hist.history['loss'], marker='.',c='orange', label='loss')
plt.plot(hist.history['val_loss'], marker='.', c='blue', label='val_loss')
plt.title('Loss & Val_loss')
plt.ylabel('loss')
plt.xlabel('epochs')
plt.legend()
plt.show()
#==============================#
#epochs 500 일때
# r2 스코어: 0.5423435655504028
# 걸린시간: 35.26150369644165
#epochs 5000 일 때
# Epoch 579: early stopping
# 129/129 [==============================] - 0s 943us/step - loss: 0.6005
# 129/129 [==============================] - 0s 804us/step
# r2 스코어: 0.5543514821537454
# 걸린시간: 57.997618675231934
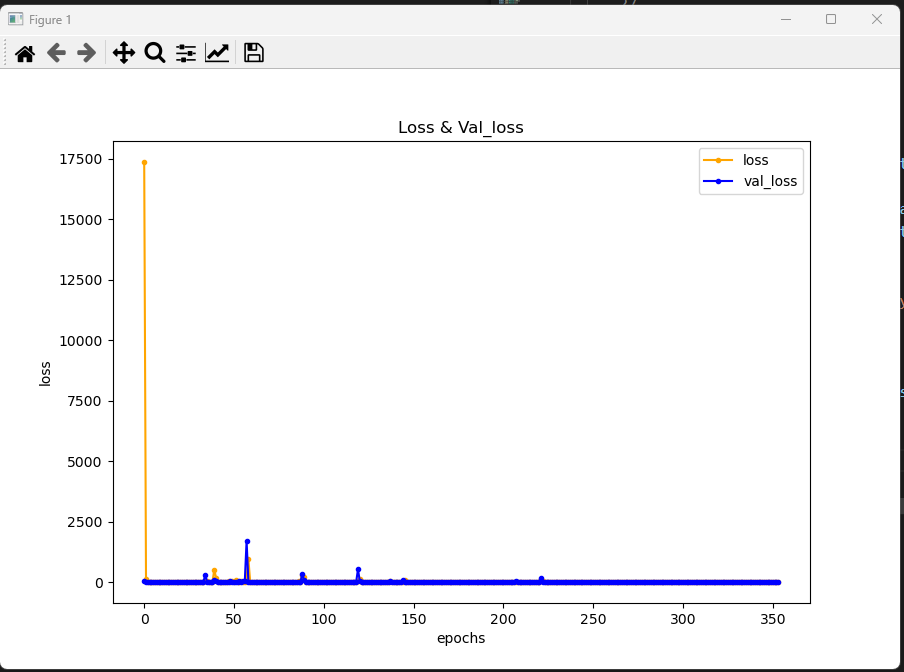
cancer earlystopping
#이진분류= 회귀 = 캘리포니아
#early stopping
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score, accuracy_score # r2=적합도, ac=정확도
from sklearn.datasets import load_breast_cancer
import time
#1. 데이터
datasets = load_breast_cancer()
print(datasets.DESCR)
print(datasets.feature_names)
# ['mean radius' 'mean texture' 'mean perimeter' 'mean area'
# 'mean smoothness' 'mean compactness' 'mean concavity'
# 'mean concave points' 'mean symmetry' 'mean fractal dimension'
# 'radius error' 'texture error' 'perimeter error' 'area error'
# 'smoothness error' 'compactness error' 'concavity error'
# 'concave points error' 'symmetry error' 'fractal dimension error'
# 'worst radius' 'worst texture' 'worst perimeter' 'worst area'
# 'worst smoothness' 'worst compactness' 'worst concavity'
# 'worst concave points' 'worst symmetry' 'worst fractal dimension']
x = datasets.data
y = datasets.target
print(x.shape, y.shape) #(569, 30) (569,)
x_train, x_test, y_train, y_test = train_test_split(
x, y, train_size=0.6, test_size=0.2, random_state=100, shuffle=True
)
#2. 모델구성
model=Sequential()
model.add(Dense(100, input_dim=30))
model.add(Dense(100))
model.add(Dense(50, activation='relu'))
model.add(Dense(1, activation='sigmoid')) #0이냐 1이냐 찾는 이진분류이기때문에 뉴런 1, 이진분류는 무조건 아웃풋 활성화 함수를: sigmoid
#3. 컴파일, 훈련
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy','mse']) #손실함수는 바이너리 넣어야함, metrics, accuracy 역할할 확인 하기**
## early stopping
from keras.callbacks import EarlyStopping
earlystoppinng = EarlyStopping(monitor='val_loss', patience=200, mode='min',
verbose=1, restore_best_weights=True)
start_time= time.time()
hist = model.fit(x_train, y_train, epochs=5000, batch_size=200,
validation_split=0.2,
callbacks=[earlystoppinng],
verbose=1)
end_time = time.time() - start_time
#4. 평가 예측
# loss =model.evaluate(x_test,y_test)
loss, acc, mse = model.evaluate(x_test, y_test)
y_predict =model.predict(x_test) #소수점 나와서 0인지 1인지 만들어줘야함
y_predict = np.round(y_predict)
acc = accuracy_score(y_test, y_predict)
print('loss : ', loss) #loss : [0.3225121796131134, 0.9064327478408813, 0.08121472597122192]
print('accuracy : ', acc) #accuracy : 0.9064327485380117
print('걸린 시간: ', end_time) #걸린 시간: 1.084829568862915
#시그모이드랑 바이너리 넣으면 끝, 분류기 때문에 r2scoore가 아니라 accurancy score 체크
#시각화
import matplotlib.pyplot as plt
plt.figure(figsize=(9,6))
plt.plot(hist.history['loss'], marker='.', c='orange', label='loss')
plt.plot(hist.history['val_loss'], marker='.', c='blue', label='val_loss')
plt.title('Loss & Val_loss')
plt.ylabel('loss')
plt.xlabel('epochs')
plt.legend()
plt.show()
#==============================#
#epochs 5000, patience 50 일 때
# Epoch 102: early stopping
# loss : 0.26109713315963745
# accuracy : 0.9473684210526315
# 걸린 시간: 2.953126907348633
#epochs 5000, patience 100 일 때
# Epoch 265: early stopping
# loss : 0.19277802109718323
# accuracy : 0.9385964912280702
# 걸린 시간: 7.374332427978516
#epochs 5000, patience 200 일 때
# Epoch 718: early stopping
# loss : 0.1545599400997162
# accuracy : 0.9385964912280702
# 걸린 시간: 19.094697952270508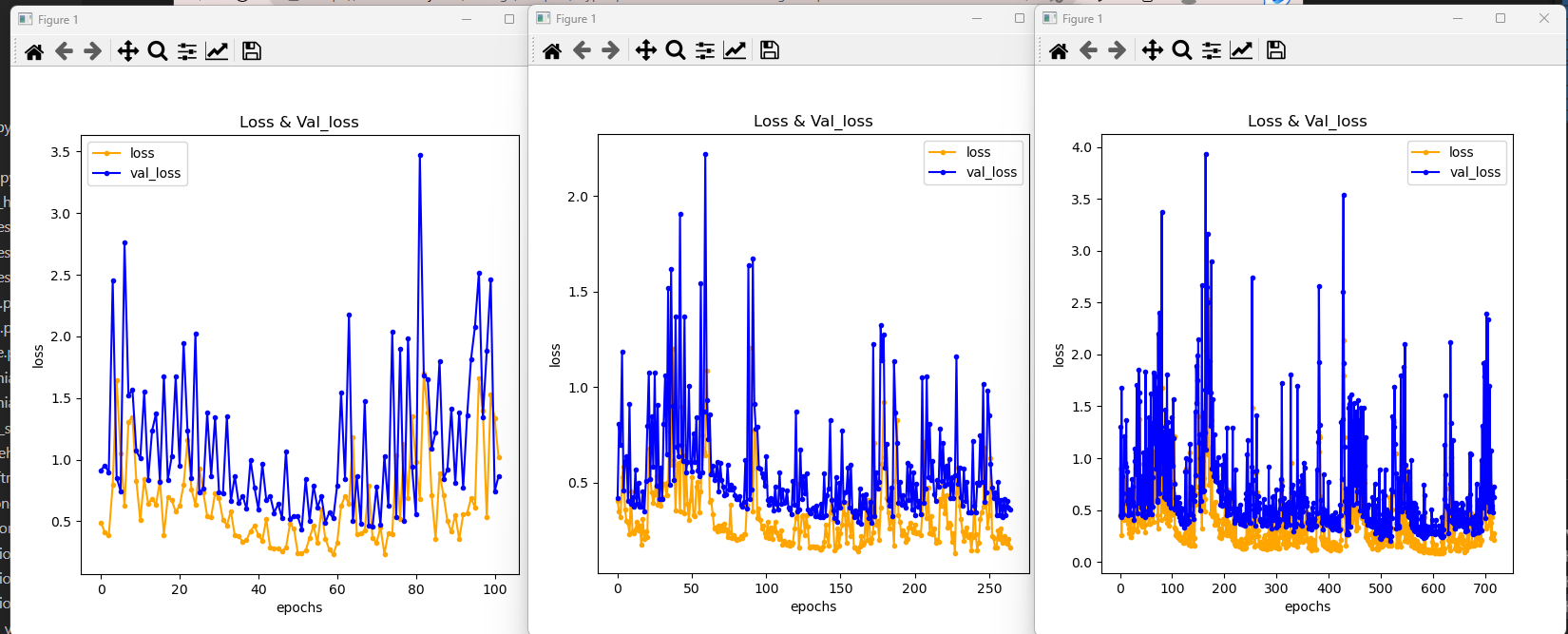
wine earlystopping
#[실습] one hot encoding을 사용하여 분석
# validation & earlystopping
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_wine
import time
#1. 데이터
datasets = load_wine()
x = datasets.data
y = datasets.target
from keras.utils import to_categorical
y = to_categorical(y)
x_train, x_test, y_train, y_test = train_test_split(
x,y,train_size=0.6, test_size=0.2, random_state=100, shuffle=True
)
#2. 모델링
model=Sequential()
model.add(Dense(100, input_dim=13))
model.add(Dense(100))
model.add(Dense(50))
model.add(Dense(10))
model.add(Dense(3, activation='softmax'))
#3. 컴파일, 훈련
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics='accuracy')
## early stopping
from keras.callbacks import EarlyStopping
earlystopping = EarlyStopping(monitor='val_loss', patience=10, mode='min',
verbose=1, restore_best_weights=True)
start_time = time.time()
hist = model.fit(x_train, y_train, epochs=100000, batch_size=100, validation_split=0.2,
callbacks=[earlystopping], verbose=1)
end_time = time.time() - start_time
print('걸린 시간: ', end_time)
# 예측, 평가
loss, acc = model.evaluate(x_test,y_test)
print('loss: ', loss)
print('acc: ', acc)
#loss: 0.15465861558914185
#acc: 0.9629629850387573
#시각화
import matplotlib.pyplot as plt
plt.figure(figsize=(9,6))
plt.plot(hist.history['loss'], marker='.', c='orange', label='loss')
plt.plot(hist.history['val_loss'], marker='.', c='pink', label='val_loss')
plt.title('Loss & Val_loss')
plt.ylabel('loss')
plt.xlabel('epochs')
plt.legend()
plt.show()
#==============================#
#epochs 100000, patience 10 일 때
# Epoch 68: early stopping
# loss: 1.413638710975647
# acc: 0.6666666865348816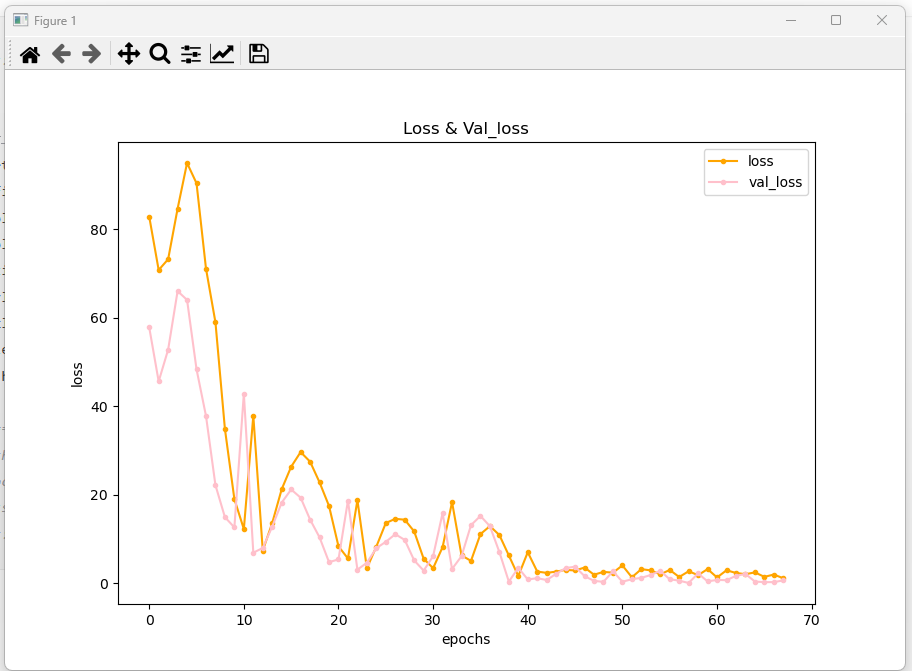
tf15_model_save_cali /// 모델만 save 됨
따라서 time은 안 됨
save를 언제 쓰냐 , 제출용, 다른 회사가서 써먹을때, 흠,,
#validation_split & ealry stopping & model_save
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score
from sklearn.datasets import fetch_california_housing
import time
#1. 데이터
#datasets = load_boston()
datasets = fetch_california_housing()
x = datasets.data #변수, 컬럼, 열
y = datasets.target
print(datasets.feature_names)
print(datasets.DESCR)
print(x.shape) #(20640, 8)
print(y.shape) # (20640,)
x_train, x_test, y_train, y_test = train_test_split(
x,y, test_size=0.2, random_state=100, shuffle=True
)
print(x_train.shape) #(14447, 8)
print(y_train.shape) #(14447,)
#2. 모델구성
model=Sequential()
model.add(Dense(100, input_dim=8))
model.add(Dense(100))
model.add(Dense(100))
model.add(Dense(1))
model.save('./_save/tf15_cali.h5') # h5로 모델 저장 #############
#3. 컴파일,훈련
model.compile(loss='mse', optimizer='adam')
## early stopping
from keras.callbacks import EarlyStopping
earlyStopping = EarlyStopping(monitor='val_loss', patience=50, mode='min',
verbose=1, restore_best_weights=True )
start_time = time.time()
hist = model.fit(x_train, y_train, epochs=5000, batch_size=200,
validation_split=0.2,
callbacks=[earlyStopping],
verbose=1)
end_time = time.time() - start_time
#4. 예측,평가
loss = model.evaluate(x_test, y_test)
y_predict = model.predict(x_test)
r2 = r2_score(y_test, y_predict)
print('r2 스코어: ', r2)
print('걸린시간: ', end_time)
#==============================#
#epochs=5000, patience 50 일 때
# Epoch 149: early stopping
# r2 스코어: 0.5297356286390125
# 걸린시간: 22.609537601470947tf15_model_load_cali ///// 모델만 load
:keras model 에 load_model 추가하기
#validation_split & ealry stopping & model_save
#import 추가: from keras.models import Sequential, load_model
import numpy as np
from keras.models import Sequential, load_model
from keras.layers import Dense
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score
from sklearn.datasets import fetch_california_housing
import time
#1. 데이터
#datasets = load_boston()
datasets = fetch_california_housing()
x = datasets.data #변수, 컬럼, 열
y = datasets.target
print(datasets.feature_names)
print(datasets.DESCR)
print(x.shape) #(20640, 8)
print(y.shape) # (20640,)
x_train, x_test, y_train, y_test = train_test_split(
x,y, test_size=0.2, random_state=100, shuffle=True
)
print(x_train.shape) #(14447, 8)
print(y_train.shape) #(14447,)
#2. 모델구성
# model=Sequential()
# model.add(Dense(100, input_dim=8))
# model.add(Dense(100))
# model.add(Dense(100))
# model.add(Dense(1))
# model.save('./_save/tf15_cali.h5') # h5로 모델 저장
model = load_model('./_save/tf15_cali.h5')
#3. 컴파일,훈련
model.compile(loss='mse', optimizer='adam')
## early stopping
from keras.callbacks import EarlyStopping
earlyStopping = EarlyStopping(monitor='val_loss', patience=50, mode='min',
verbose=1, restore_best_weights=True )
start_time = time.time()
hist = model.fit(x_train, y_train, epochs=5000, batch_size=200,
validation_split=0.2,
callbacks=[earlyStopping],
verbose=1)
end_time = time.time() - start_time
#4. 예측,평가
loss = model.evaluate(x_test, y_test)
y_predict = model.predict(x_test)
r2 = r2_score(y_test, y_predict)
print('r2 스코어: ', r2)
print('걸린시간: ', end_time)
#==============================#
# save model 값
#epochs=5000, patience 50 일 때
# Epoch 149: early stopping
# r2 스코어: 0.5297356286390125
# 걸린시간: 22.609537601470947
# load model 값
# Epoch 83: early stopping
# r2 스코어: 0.4987951497314347
# 걸린시간: 10.35082626342773416.컴파일 & 훈련까지 save & load
model save & load 니까 따라서 time은 안 됨
save
#validation_split & ealry stopping & model_save
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score
from sklearn.datasets import fetch_california_housing
import time
#1. 데이터
#datasets = load_boston()
datasets = fetch_california_housing()
x = datasets.data #변수, 컬럼, 열
y = datasets.target
print(datasets.feature_names)
print(datasets.DESCR)
print(x.shape) #(20640, 8)
print(y.shape) # (20640,)
x_train, x_test, y_train, y_test = train_test_split(
x,y, test_size=0.2, random_state=100, shuffle=True
)
print(x_train.shape) #(14447, 8)
print(y_train.shape) #(14447,)
#2. 모델구성
model=Sequential()
model.add(Dense(100, input_dim=8))
model.add(Dense(100))
model.add(Dense(100))
model.add(Dense(1))
#3. 컴파일,훈련
model.compile(loss='mse', optimizer='adam')
## early stopping
from keras.callbacks import EarlyStopping
earlyStopping = EarlyStopping(monitor='val_loss', patience=50, mode='min',
verbose=1, restore_best_weights=True )
start_time = time.time()
hist = model.fit(x_train, y_train, epochs=5000, batch_size=200,
validation_split=0.2,
callbacks=[earlyStopping],
verbose=1)
end_time = time.time() - start_time
model.save('./_save/tf16_cali.h5') # h5로 모델 저장 ########################
#4. 예측,평가
loss = model.evaluate(x_test, y_test)
y_predict = model.predict(x_test)
r2 = r2_score(y_test, y_predict)
print('r2 스코어: ', r2)
print('걸린시간: ', end_time)
#==============================#
# Epoch 143: early stopping
# r2 스코어: 0.5254035118715907
# 걸린시간: 17.09897398948669416.load
#validation_split & ealry stopping & model_save
#import 추가: from keras.models import Sequential, load_model
#load_model
import numpy as np
from keras.models import Sequential, load_model
from keras.layers import Dense
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score
from sklearn.datasets import fetch_california_housing
import time
#1. 데이터
#datasets = load_boston()
datasets = fetch_california_housing()
x = datasets.data #변수, 컬럼, 열
y = datasets.target
print(datasets.feature_names)
print(datasets.DESCR)
print(x.shape) #(20640, 8)
print(y.shape) # (20640,)
x_train, x_test, y_train, y_test = train_test_split(
x,y, test_size=0.2, random_state=100, shuffle=True
)
print(x_train.shape) #(14447, 8)
print(y_train.shape) #(14447,)
#2. 모델구성
# model=Sequential()
# model.add(Dense(100, input_dim=8))
# model.add(Dense(100))
# model.add(Dense(100))
# model.add(Dense(1))
# model.save('./_save/tf15_cali.h5') # h5로 모델 저장
'''
#3. 컴파일,훈련
model.compile(loss='mse', optimizer='adam')
## early stopping
from keras.callbacks import EarlyStopping
earlyStopping = EarlyStopping(monitor='val_loss', patience=50, mode='min',
verbose=1, restore_best_weights=True )
start_time = time.time()
hist = model.fit(x_train, y_train, epochs=5000, batch_size=200,
validation_split=0.2,
callbacks=[earlyStopping],
verbose=1)
end_time = time.time() - start_time
'''
model = load_model('./_save/tf16_cali.h5')
#4. 예측,평가
loss = model.evaluate(x_test, y_test)
y_predict = model.predict(x_test)
r2 = r2_score(y_test, y_predict)
print('r2 스코어: ', r2)
#print('걸린시간: ', end_time)
#==============================#
#save model
# Epoch 143: early stopping
# r2 스코어: 0.5254035118715907
# 걸린시간: 17.098973989486694
#load model
#r2 스코어: 0.5254035118715907가중치만
tf17_weight_save_cali
저장되는 weight ; : 아래 부분에서 weight만 뽑아서 저장
#가중치값 저장
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score
from sklearn.datasets import fetch_california_housing
import time
#1. 데이터
#datasets = load_boston()
datasets = fetch_california_housing()
x = datasets.data #변수, 컬럼, 열
y = datasets.target
print(datasets.feature_names)
print(datasets.DESCR)
print(x.shape) #(20640, 8)
print(y.shape) # (20640,)
x_train, x_test, y_train, y_test = train_test_split(
x,y, test_size=0.2, random_state=100, shuffle=True
)
print(x_train.shape) #(14447, 8)
print(y_train.shape) #(14447,)
#2. 모델구성
model=Sequential()
model.add(Dense(100, input_dim=8))
model.add(Dense(100))
model.add(Dense(100))
model.add(Dense(1))
#3. 컴파일,훈련
model.compile(loss='mse', optimizer='adam')
## early stopping
from keras.callbacks import EarlyStopping
earlyStopping = EarlyStopping(monitor='val_loss', patience=50, mode='min',
verbose=1, restore_best_weights=True )
start_time = time.time()
hist = model.fit(x_train, y_train, epochs=5000, batch_size=200,
validation_split=0.2,
callbacks=[earlyStopping],
verbose=1)
end_time = time.time() - start_time
model.save_weights('./_save/tf17_weight_cali.h5') ###########weight값 저장
#4. 예측,평가
loss = model.evaluate(x_test, y_test)
y_predict = model.predict(x_test)
r2 = r2_score(y_test, y_predict)
print('r2 스코어: ', r2)
print('걸린시간: ', end_time)
#==============================#
# Epoch 222: early stopping
# r2 스코어: 0.5424216600004373
# 걸린시간: 26.303983449935913과적합을 피하기 위해
1. early stopping
2. 드랍아웃: 노드 쌓여있는 사이에 넣어서 몇개 없애버리깅 ;
weight load
#가중치값 저장장
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score
from sklearn.datasets import fetch_california_housing
import time
#1. 데이터
#datasets = load_boston()
datasets = fetch_california_housing()
x = datasets.data #변수, 컬럼, 열
y = datasets.target
print(datasets.feature_names)
print(datasets.DESCR)
print(x.shape) #(20640, 8)
print(y.shape) # (20640,)
x_train, x_test, y_train, y_test = train_test_split(
x,y, test_size=0.2, random_state=100, shuffle=True
)
print(x_train.shape) #(14447, 8)
print(y_train.shape) #(14447,)
#2. 모델구성
model=Sequential()
model.add(Dense(100, input_dim=8))
model.add(Dense(100))
model.add(Dense(100))
model.add(Dense(1))
model.load_weights('./_save/tf17_weight_cali.h5')
#3. 컴파일,훈련
model.compile(loss='mse', optimizer='adam') #컴파일은 지우면 안됨됨
'''
## early stopping
from keras.callbacks import EarlyStopping
earlyStopping = EarlyStopping(monitor='val_loss', patience=50, mode='min',
verbose=1, restore_best_weights=True )
start_time = time.time()
hist = model.fit(x_train, y_train, epochs=5000, batch_size=200,
validation_split=0.2,
callbacks=[earlyStopping],
verbose=1)
end_time = time.time() - start_time
'''
#4. 예측,평가
loss = model.evaluate(x_test, y_test)
y_predict = model.predict(x_test)
r2 = r2_score(y_test, y_predict)
print('r2 스코어: ', r2)
#print('걸린시간: ', end_time)
#==============================#
#weight save
# Epoch 222: early stopping
# r2 스코어: 0.5424216600004373
# 걸린시간: 26.303983449935913
#weight load
# r2 스코어: 0.5424216600004373중간에 model.fit 날릴 수 있는 이유
model.evaluate()와 model.predict() 함수 모두, 모델에 입력 데이터를 넣어 계산된 출력 값을 반환합니다. 이때, 가중치를 이용하여 계산됩니다.
model.evaluate() 함수는 정확도(accuracy) 등의 평가 지표와 손실(loss) 값을 반환하며, model.predict() 함수는 모델이 예측한 출력 값을 반환합니다.

위 코드는 가중치를 학습시키는 코드입니다. 모델이 입력 데이터(x_train)와 정답 데이터(y_train)를 이용해 학습을 진행하고, 이때 사용되는 가중치가 최적화되어 갱신됩니다.
또한, EarlyStopping 콜백 함수가 포함되어 있어서 학습 도중에 validation loss가 더이상 향상되지 않으면 학습을 중단합니다. 이렇게 함으로써, 오버피팅을 방지하고 학습 효율성을 높일 수 있습니다.
hist는 모델의 학습 과정에서의 손실값(loss)과 정확도(accuracy) 등을 기록하는 변수입니다. 이 변수를 이용하여 모델이 학습한 결과를 시각화하거나 분석할 수 있습니다.
tf18_MCP_save_cali//# Model Check Point
#모델체크 포인트
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score
from sklearn.datasets import fetch_california_housing
import time
#1. 데이터
#datasets = load_boston()
datasets = fetch_california_housing()
x = datasets.data #변수, 컬럼, 열
y = datasets.target
print(datasets.feature_names)
print(datasets.DESCR)
print(x.shape) #(20640, 8)
print(y.shape) # (20640,)
x_train, x_test, y_train, y_test = train_test_split(
x,y, test_size=0.2, random_state=100, shuffle=True
)
print(x_train.shape) #(14447, 8)
print(y_train.shape) #(14447,)
#2. 모델구성
model=Sequential()
model.add(Dense(100, input_dim=8))
model.add(Dense(100))
model.add(Dense(100))
model.add(Dense(1))
#3. 컴파일,훈련
model.compile(loss='mse', optimizer='adam')
## early stopping
from keras.callbacks import EarlyStopping, ModelCheckpoint ### 모델체크포인트 추가가
earlyStopping = EarlyStopping(monitor='val_loss', patience=50, mode='min',
verbose=1, restore_best_weights=True )
# Model Check Point - 따로 보관하기기
mcp = ModelCheckpoint(
monitor='val_loss',
mode='auto',
verbose=1,
save_best_only=True,
filepath='./_mcp/tf18_cali.hdf5' #파일명 체크
)
start_time = time.time()
hist = model.fit(x_train, y_train, epochs=5000, batch_size=200,
validation_split=0.2,
callbacks=[earlyStopping, mcp], ########### mcp 스탑할때까지 계속 좋은 값 저장하면서 업데이트
verbose=1)
end_time = time.time() - start_time
model.save_weights('./_save/tf17_weight_cali.h5')
#4. 예측,평가
loss = model.evaluate(x_test, y_test)
y_predict = model.predict(x_test)
r2 = r2_score(y_test, y_predict)
print('r2 스코어: ', r2)
print('걸린시간: ', end_time)
#==============================#
# Epoch 321: early stopping
# r2 스코어: 0.5486243827633063
# 걸린시간: 43.54737997055054
########### mcp 스탑할때까지 계속 좋은 값 저장하면서 업데이트
# Epoch 298: saving model to ./_mcp\tf18_cali.hdf5
# 67/67 [==============================] - 0s 2ms/step - loss: 0.6473 - val_loss: 0.6705
# Epoch 299/5000
# 43/67 [==================>...........] - ETA: 0s - loss: 0.6495
# Epoch 299: saving model to ./_mcp\tf18_cali.hdf5
# 67/67 [==============================] - 0s 2ms/step - loss: 0.6595 - val_loss: 0.6997
# Epoch 300/5000
# 41/67 [=================>............] - ETA: 0s - loss: 0.7062
# Epoch 300: saving model to ./_mcp\tf18_cali.hdf5
# 67/67 [==============================] - 0s 2ms/step - loss: 0.7103 - val_loss: 1.0095tf18_MCP_load_cali//# Model Check Point
#모델체크 포인트 로드. 모델을 다 지워도 됨 ,, ,!!! 모델과 같음
import numpy as np
from keras.models import Sequential, load_model ##################추가가
from keras.layers import Dense
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score
from sklearn.datasets import fetch_california_housing
import time
#1. 데이터
#datasets = load_boston()
datasets = fetch_california_housing()
x = datasets.data
y = datasets.target
print(datasets.feature_names)
print(datasets.DESCR)
print(x.shape)
print(y.shape)
x_train, x_test, y_train, y_test = train_test_split(
x,y, test_size=0.2, random_state=100, shuffle=True
)
print(x_train.shape)
print(y_train.shape)
# #2. 모델구성
# model=Sequential()
# model.add(Dense(100, input_dim=8))
# model.add(Dense(100))
# model.add(Dense(100))
# model.add(Dense(1))
# #3. 컴파일,훈련
# model.compile(loss='mse', optimizer='adam')
## early stopping
from keras.callbacks import EarlyStopping, ModelCheckpoint ### 모델체크포인트 추가가
# earlyStopping = EarlyStopping(monitor='val_loss', patience=50, mode='min',
# verbose=1, restore_best_weights=True )
# Model Check Point - 따로 보관하기기
# mcp = ModelCheckpoint(
# monitor='val_loss',
# mode='auto',
# verbose=1,
# save_weights_only=True,
# filepath='./_mcp/tf18_cali.hdf5' #파일명 체크
# )
# start_time = time.time()
# hist = model.fit(x_train, y_train, epochs=5000, batch_size=200,
# validation_split=0.2,
# callbacks=[earlyStopping, mcp],
# verbose=1)
# end_time = time.time() - start_time
model = load_model('./_mcp/tf18_cali.hdf5')
#4. 예측,평가
loss = model.evaluate(x_test, y_test)
y_predict = model.predict(x_test)
r2 = r2_score(y_test, y_predict)
print('r2 스코어: ', r2)
# print('걸린시간: ', end_time)
#==============================#
# Epoch 321: early stopping
# r2 스코어: 0.5486243827633063
# 걸린시간: 43.54737997055054
#load
# r2 스코어: 0.541111940525899model.save_weights() 함수를 사용하면
모든 가중치가 저장되어있는 것일 뿐이기에 최적의 값을 찾기 위해 모델 구성 및 컴파일 단계를 거쳐야하고.
반면에, ModelCheckpoint 콜백 함수를 사용하면 모델 구조와, 설정한 최적 가중치 값을 저장한다.
따라서 model 들어가는 라인 다 날릴 수 있음
'[네이버클라우드] 클라우드 기반의 개발자 과정 7기 > AI' 카테고리의 다른 글
| Ai 개념정리 4 - 합성곱 신경망 (0) | 2023.05.11 |
|---|---|
| Ai 개념 정리 3 (1) | 2023.05.10 |
| ai 개념정리 2 (1) | 2023.05.10 |
| [수업자료] Ai 2일차 코드 (1) | 2023.05.09 |
| AI 개념 정리 (2) | 2023.05.08 |