1. 인공지능 개념 정리 – 머신러닝, 딥러닝
2. 퍼셉트론 (Perceptron)
3. 다층 퍼셉트론 (Multi-Layer Perceptron: MLP)
4. 옵티마이저 (Optimizer)
5. 학습률 (learning rate)
6. 경사하강법 (Gradient Descent)
7. 손실함수 (Loss Function)
8. 활성화 함수 (Activation Function) – Sigmoid, ReLU, Softmax
1. 인공지능 개념 정리 – 머신러닝, 딥러닝
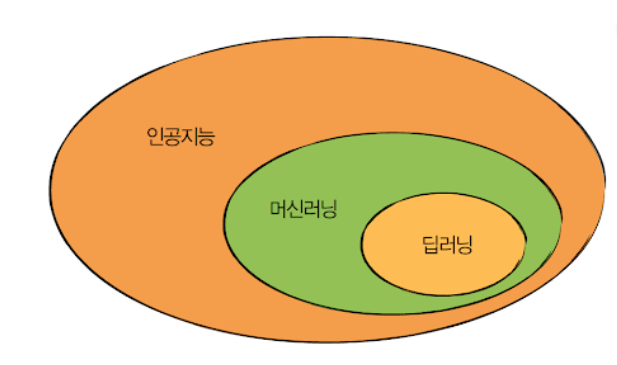
인공지능(Artificial intelligence): 인공지능은 사람처럼 학습하고 추론할 수 있는 지능을 가진 시스템을 만드는 기술입니다. 인공지능은 강인공지능과 약인공지능으로 나눌 수 있습니다
머신러닝(Machine Learning): 규칙을 프로그래밍하지 않아도 자동으로 데이터에서 규칙을 학습하는 알고리즘을 연구하는 분야입니다. 사이킷런이 대표적인 라이브러. 컴퓨터의 알고리즘이 내포되어 있다.
딥러닝(Deap learnging): 딥러닝은 인공 신경망이라고도 하며, 일련의 단계들 또는 연산을 사용하는 머신러닝 알고리즘(일련의 수학적 계산 과정들로 구성된 알고리즘)
2. 퍼셉트론 (Perceptron)
단순 구조, 인공 신경망의 한 종류, 뉴런의 모델을 모방하여 입력층, 출력층으로 구성한 모델
에러가 뜨면 계속 반복해서 입력값을 넣어 최적의 w값을 찾고 찾으면 종료
구성요소: 입력값, 가중치, 활성화함수, 출력값(예측값)
3. 다층 퍼셉트론 (Multi-Layer Perceptron: MLP)
통상 말하는 딥러닝, 노드(뉴런)는 엣지(edge)라고 하는 선으로 연결됨
입력층(input layer), 은닉층(hidden layer), 출력층(output layer)로 구성됨
노드: 입력값을 받아 가중치와 활성화 함수를 통해 출력값을 계산하는 단위, 여러 개의 노드가 모여 레이어 구성
다수의 레이어가 쌓여 인공신경망 형성

4. 옵티마이저 (Optimizer)
인공신경망(딥러닝)을 학습시키기 위해서는 모델 내부에 있는 가중치(weight)와 편향(bias) 값을 조정해야 합니다. 이를 위해서는 손실 함수(loss function)를 정의하고, 손실 함수의 값을 최소화하는 방향으로 가중치와 편향 값을 업데이트 해줘야 합니다. 이때 사용하는 알고리즘을 옵티마이저(optimizer)라고 합니다.
옵티마이저는 가중치와 편향 값을 업데이트할 때, 현재 가중치와 편향 값, 그리고 손실 함수의 기울기 등을 이용하여 새로운 값을 계산합니다. 이때 계산된 값은 현재 가중치와 편향 값을 적절히 변화시켜서, 다음 학습 단계에서 더 나은 결과를 얻을 수 있도록 합니다.
일반적으로 사용되는 옵티마이저에는 확률적 경사 하강법(SGD, Stochastic Gradient Descent)과 그 변형인 모멘텀(Momentum), 아다그라드(Adagrad), 알엠에스프롭(RMSProp), 아담(Adam) 등이 있습니다. 각각의 옵티마이저는 모델의 성능과 데이터셋의 특성에 따라 선택될 수 있습니다.
5. 학습률 (learning rate)
*파라미터:모델의 가중치(weight)와 편향(bias) 같이 모델이 학습을 통해 스스로 찾아내는 값을 말합니다. 이 값들은 입력 데이터로부터 최종적인 출력값을 예측하기 위해 필요한 모델 내부의 계산과정에서 사용됩니다.
*하이퍼파라미터: 모델의 학습과정을 제어하기 위해 사용되는 매개변수로, 모델의 구조, 학습률, 배치크기등이 해당되며, 모델을 학습시키기 전에 사람이 직접 설정하며, 모델이 데이터로부터 학습할 때 최적의 성능을 발휘할 수 있도록 조절하는 역할
- Epochs: 학습데이터 전체를 몇 번 반복해서 학습할지 결정하는 하이퍼파라미터 /Epochs가 크면 학습 시간이 오래 걸리지만 더 많은 학습이 가능
- batch size: 학습 데이터를 몇 개의 미니 배치로 나누어 학습할지 결정하는 하이퍼파라미터 /배치 크기가 크면 메모리 사용량이 늘어나지만 더 빠르게 학습
- learning rate: 가중치를 업데이트할 때 얼마나 크게 업데이트할지 결정하는 하이퍼 파라미터 / 학습률이 너무 작으면 학습이 느리게 되고, 학습률이 너무 크면 발산, 학습률이 작으면 작은 간격으로 파라미터가 업데이트되고, 학습률이 크면 더 큰 간격으로 파라미터가 업데이트 된다.
6. 경사하강법 (Gradient Descent)
손실함수가 최소가 되는 지점을 찾기 위해 현재 위치에서 기울기의 반대 방향으로 일정한 거리를 이동하며 반복적으로 최적화를 수행한다. 이때 거리는 학습률로 제어된다. 기울기는 파라미터의 각 원소에 대한 손실함수의 미분값으로 구해진다. 모델 파라미터를 임의의 값으로 초기화한 후, 손실함수의 기울기를 계산하고, 학습률과 기울기의 곱을 현재 파라미터값에서 빼주는 방식으로 파라미터를 업데이트한다. 이를 반복하여 손실함수의 값이 최소가 되는 지점을 찾는다.
| 가설 함수 h(x)는 h(x) = wx + b로 가정하고, 초기값 w = 1, b = 0으로 설정합니다. 그리고, 학습률 α = 0.1로 설정합니다. 경사하강법을 사용하여 최적화를 수행하면서 w와 b를 조정합니다.
|
7. 손실함수 (Loss Function)
손실함수(loss function)는 인공신경망에서 사용되는 함수로, 모델이 예측한 값과 실제 정답의 차이를 계산하여, 모델이 얼마나 잘 예측하고 있는지 측정하는데 사용됩니다. 손실함수는 모델의 예측값과 정답을 입력 받아서 그 차이를 계산합니다. 이렇게 계산된 손실 값은 역전파(backpropagation) 과정에서 모델의 가중치(weight)와 편향(bias)을 업데이트 하는데 사용됩니다. 손실함수의 종류에는 MSE(Mean Squared Error), MAE(Mean Absolute Error), 교차 엔트로피(Cross-Entropy) 등이 있습니다. 각 손실함수는 다른 방식으로 모델의 성능을 평가하고, 최적화할 수 있도록 도와줍니다.
// 딥러닝 모델의 학습은 크게 "학습 데이터"와 "검증 데이터"로 나눠서 진행됩니다. 학습 데이터는 모델이 학습하는데 사용되며, 검증 데이터는 학습된 모델이 잘 작동하는지 평가하는데 사용됩니다. 검증 데이터는 학습 데이터와 달리 모델이 본 적이 없는 새로운 데이터로, 학습된 모델이 이 데이터에 대해서도 잘 예측하는지를 판단할 수 있습니다. 따라서, 모델이 학습할 때는 정답을 이미 알고 있는 학습 데이터를 사용하여 예측값을 생성하고, 이를 정답과 비교하여 손실 함수를 계산합니다. 학습 과정에서 모델은 손실 함수 값을 최소화하기 위해 가중치를 조정하며, 이를 통해 정답을 모르는 새로운 데이터에 대해서도 예측을 수행할 수 있게 됩니다.
8. 활성화 함수 (Activation Function) – Sigmoid, ReLU, Softmax
인공 신경망에서 가장 많이 사용되는 함수 중 하나. 활성화 함수는 인공 신경망의 출력값을 결정하는 함수로, 입력값을 받아 출력값을 반환한다. 일반적으로 비선형 함수가 사용되며, 선형 함수를 활성화 함수로 사용하면 해결 불가
비선형 문제) 숫자 6과 9를 구분. 각각 위아래로 뒤집어 놓은 숫자를 보면, 어떤 직선으로도 완벽하게 분리 불가능
선형 문제) y=2x + 3 의 일차 방정식
- 시그모이드 함수 : 입력값을 0과 1사의 값으로 변환해주는 비선형 함수
- 하이퍼볼릭 탄젠트 함수 : 입력값을 -1과 1 사이의 값으로 변환해주는 비선형 함수
- 렐루 함수: 입력값이 양수인 경우 그대로 출력하고, 음수인 경우 0으로 출력하는 비선형 함수
- 소프트맥스 함수: 입력값을 출력값으로 변환해주는 함수, 다중 클래스 분류에서 사용
NumPy
계산을 할 수 있는 라이브러리
계산할때 가장 기본이며, import해서 수치계산
리스트와 다른 점은 행열계산함, 데이터의 행과 열을 맞춰서 전처리가능
리스트 형태
Pandas
테이블 형태의 데이터 프레임 제공
다양한 변수를 사용해서 데이터 추출하여 사용
import로 다양한 파일을 읽어와서 활용가능 (엑셀, csv, 제이슨? 등등)
'[네이버클라우드] 클라우드 기반의 개발자 과정 7기 > AI' 카테고리의 다른 글
| Ai 개념 정리 3 (1) | 2023.05.10 |
|---|---|
| [수업자료] Ai 3일차 코드 (0) | 2023.05.10 |
| ai 개념정리 2 (1) | 2023.05.10 |
| [수업자료] Ai 2일차 코드 (1) | 2023.05.09 |
| AI (0) | 2023.05.08 |