# DML(Data Manipulation Language)
데이터 등록, 변경, 삭제를 다루는 SQL 문법
**모든 테이블은 반드시 프라이머리키를 가져야함. (데이터가 안들어간 상태에서 하는게 좋음 들어가면 복잡해)
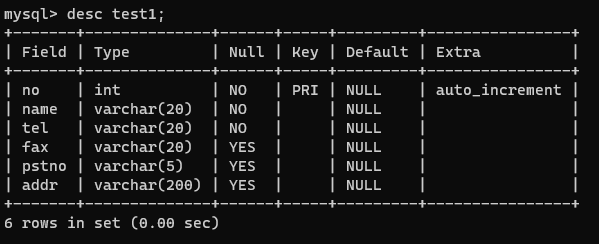
| /* 연락처 테이블 생성 */ create table test1 ( no int not null, name varchar(20) not null, tel varchar(20) not null, fax varchar(20), pstno varchar(5), addr varchar(200) ); |
| /* PK 컬럼 지정 */ (artificial key (인공키)) alter table test1 add constraint test1_pk primary key (no); |
| /* 자동 증가 컬럼 지정 */ alter table test1 modify column no int not null auto_increment; |
 |
* 컬럼값 입력하기
컬럼을 지정하지 않으면 테이블 생성한 컬럼 순서대로 값을 지정해야하고 , 컬럼을 명시하면 순서 바꿀 수 있음.
auto_incfrement는 null 값으로 입력하기.
값을 입력할 컬럼을 선택하기. 단 필수 입력 컬럼은 반드시 선택해야 한다.
(자동증가 컬럼과 기본 값 지정된 컬럼도 생략할 수 있음.)
insert into 테이블명 values(값,....);
insert into 테이블명(컬럼,컬럼,...) values(값,값,...);
여러 개 입력 :
insert into test1(name,tel) values('aaa', '1111'), ('bbb', '2222'), ('ccc', '3333');
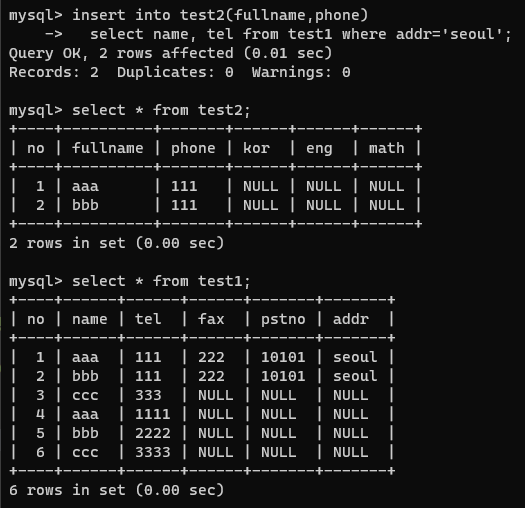
* select 결과를 테이블에 바로 입력하기
=> select 결과의 컬럼명과 insert 테이블의 컬럼명이 같을 필요는 없다.
=> 결과의 컬럼 개수와 insert 하려는 컬럼 개수가 같아야 한다.
=> 결과의 컬럼 타입과 insert 하려는 컬럼의 타입이 같거나 입력 할 수 있는 타입이어야 한다.
insert into test2(fullname,phone)
select name, tel from test1 where addr='seoul';
## update
- 등록된 데이터를 변경할 때 사용하는 명령이다.
update 테이블명 set 컬럼명=값, 컬럼명=값, ... where 조건...;
update test1 set pstno='11111', fax='222' where no=3;
(비교할때나 값을 할당할때도 = 1개만 쓰기)
## delete
- 데이터를 삭제할 때 사용하는 명령이다.
delete from 테이블명 where 조건;
delete from test1 where no=2 or no=3; /////// 왜 or인데 둘 다 삭제되지 ? ?
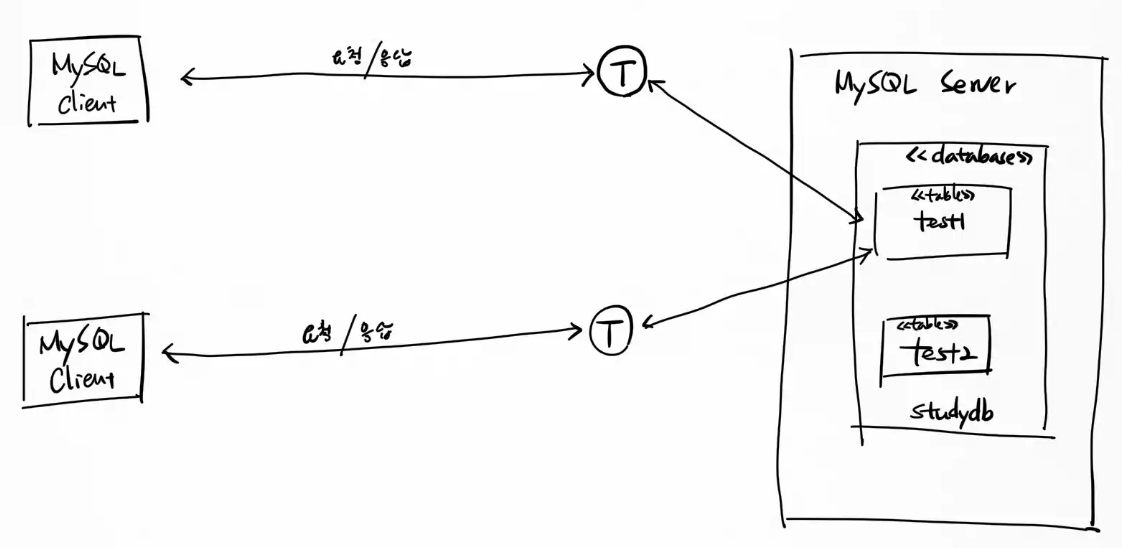
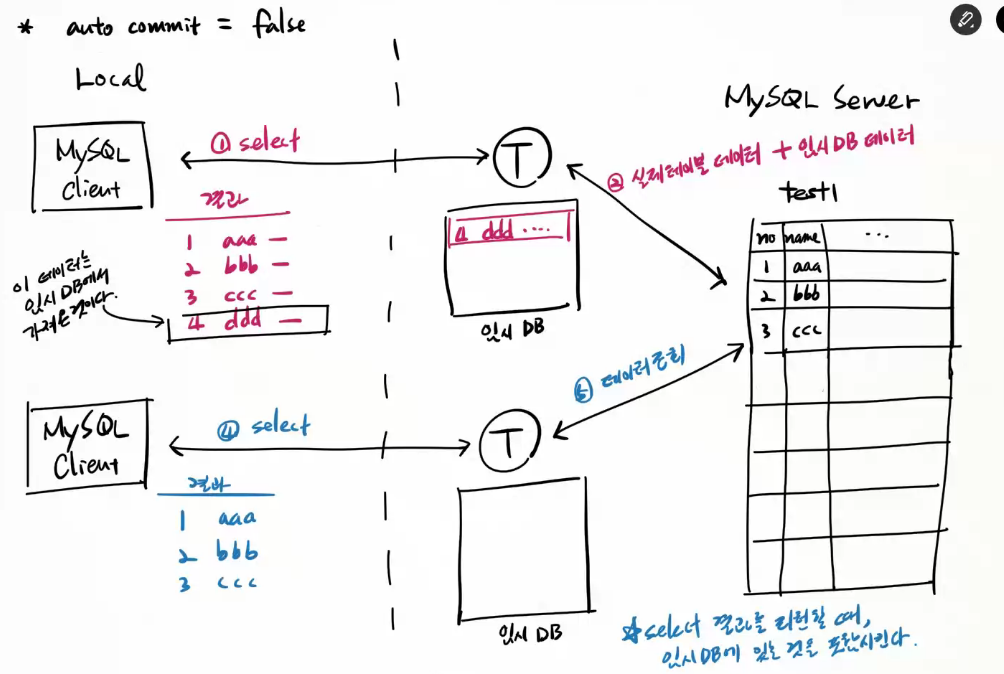
## autocommit
mysql은 autocommit의 기본 값이 true이다.
따라서 명령창에서 SQL을 실행하면 바로 실제 테이블에 적용된다.
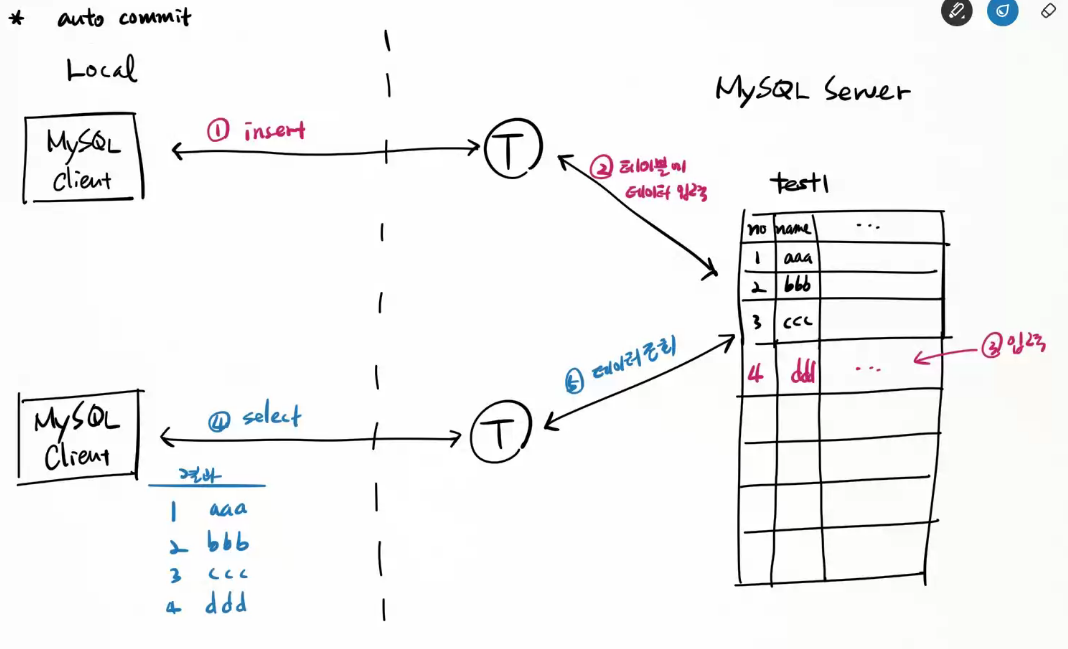
수동으로 처리하고 싶다면 autocommit을 false로 설정하라!
> set autocommit=false;
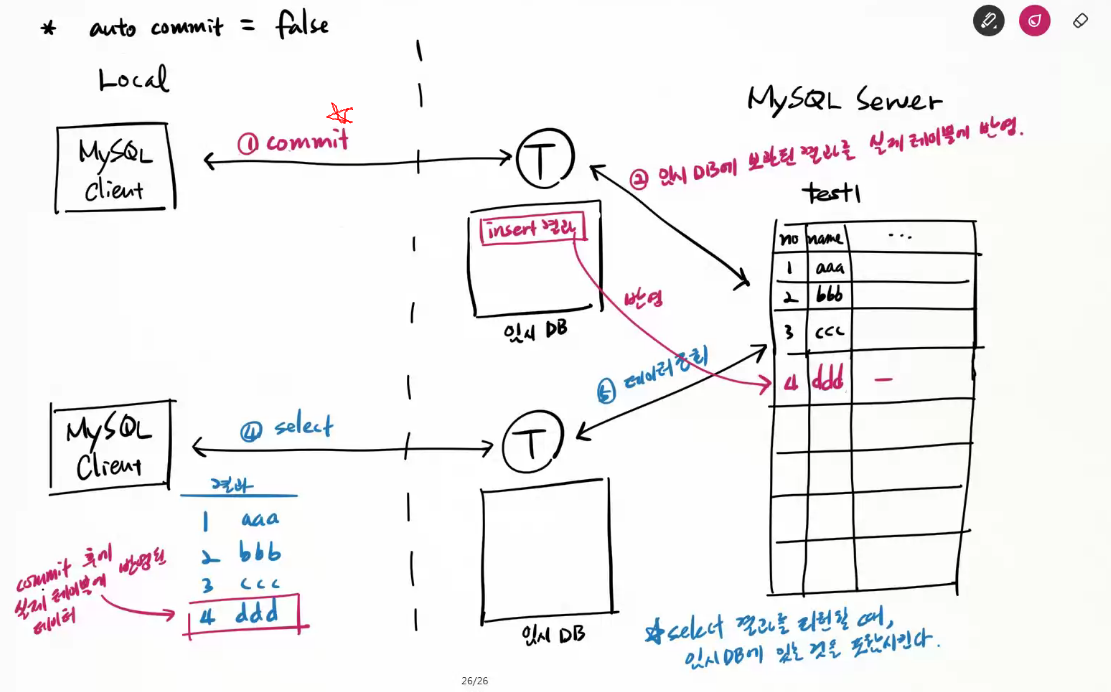
insert/update/delete을 수행한 후 승인을 해야만 실제 테이블에 적용된다.
> commmit;
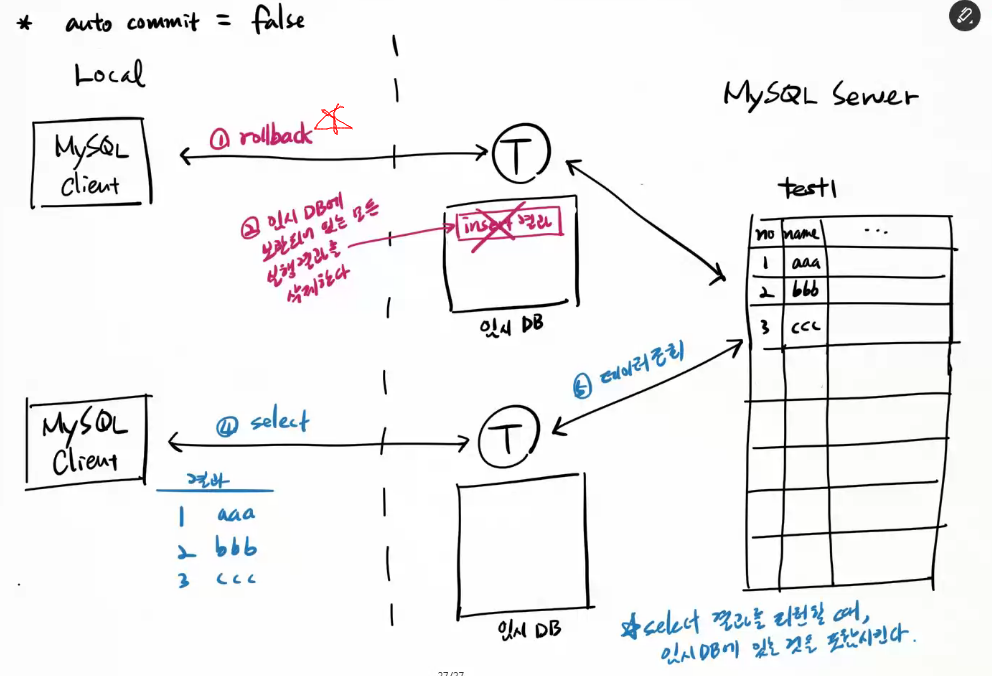
마지막 commit 상태로 되돌리고 싶다면,
> rollback;
[mysql client와 스레드 ]
[auto commit = true]
[auto commit = false]
commit
rollback
# DQL(Data Query Language)
데이터를 조회할 때 사용하는 문법
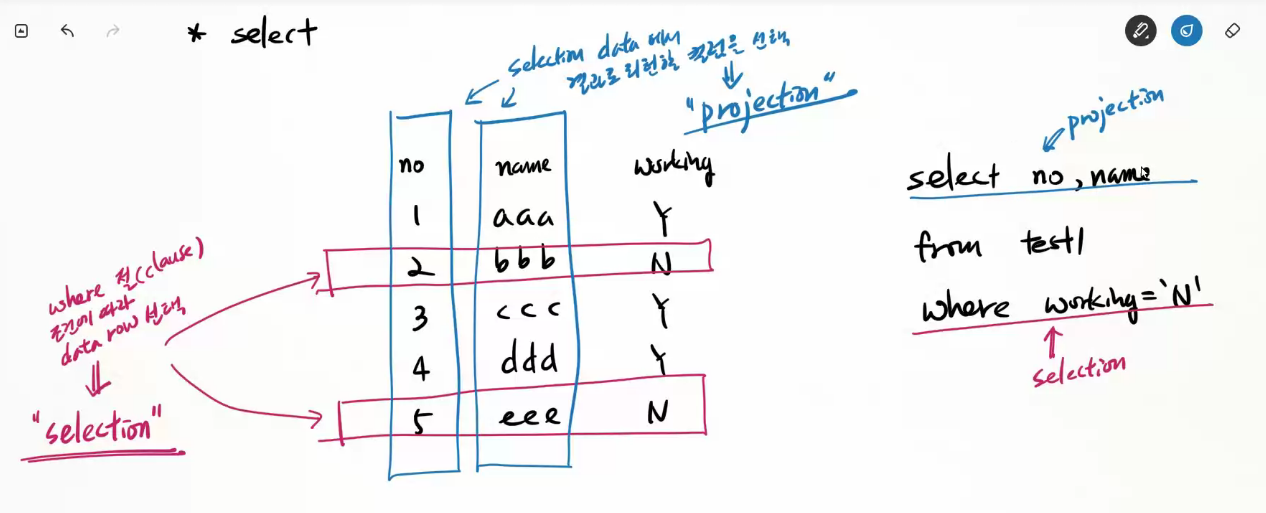
*select
projection , selection
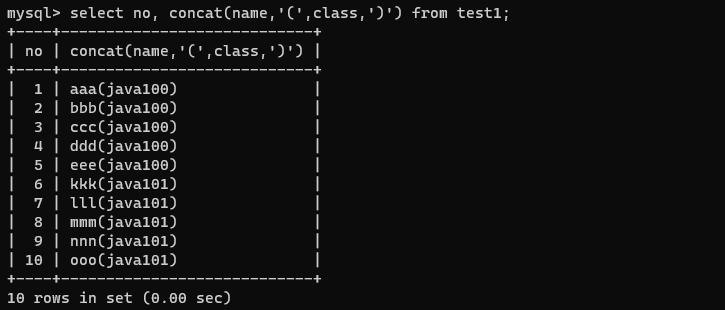
/* 가상의 컬럼 값을 조회하기*/
select no, concat(name,'(',class,')') from test1;
/* 컬럼에 별명 붙이기*/
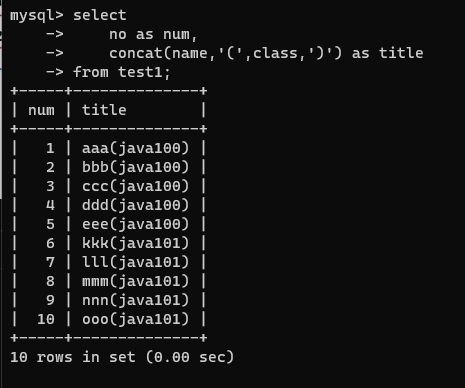
select 컬럼명 [as] 별명 ...
select
no as num,
concat(name,'(',class,')') as title
from test1;
## 연산자
### OR, AND, NOT(!=)
- OR : 두 조건 중에 참인 것이 있으면 조회 결과에 포함시킨다.
- AND : 두 조건 모두 참일 때만 조회 결과에 포함시킨다.
- NOT : 조건에 일치하지 않을 때만 결과에 포함시킨다.
/* 주의!
* where 절을 통해 결과 데이터를 먼저 선택(selection)한 다음
* 결과 데이터에서 가져올 컬럼을 선택(projection)한다.
* 따라서 실행 순서는:
* from ==> where ==> select
*/
/* 학생 번호가 3의 배수인 경우 전화번호를 '2222'로 변경하라*/
update test1 set
tel = '2222'
where (no % 3) = 0;
/* => null인지 여부를 가릴 때는 is 또는 is not 연산자를 사용하라!*/
select *
from test1
where tel is not null;
select *
from test1
where not tel is null;
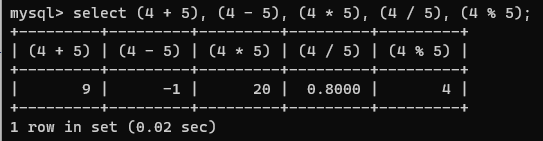
### 사칙연산
- +, -, *, /, % 연산자를 사용할 수 있다.
select (4 + 5), (4 - 5), (4 * 5), (4 / 5), (4 % 5);
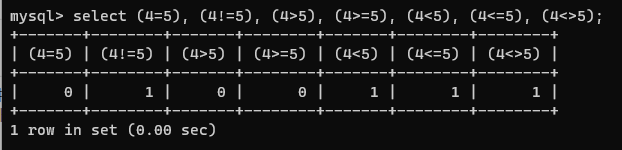
### 비교연산
- =, !=, >, >=, <, <=, <>
select (4=5), (4!=5), (4>5), (4>=5), (4<5), (4<=5), (4<>5);
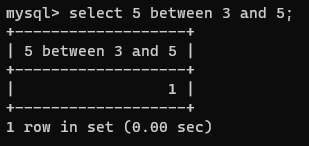
### between 값1 and 값2
- 두 값 사이(두 값도 포함)에 있는지 검사한다. 이상 이하
select 5 between 3 and 5;
like- 문자열을 비교할 때 사용한다.
| /* class 이름이 java로 시작하는 모든 학생 조회하기 * => % : 0개 이상의 문자 */ select * from test1 where class like 'java%'; /* class 이름에 java를 포함한 모든 학생 조회하기 이 경우 조회 속도가 느리다.*/ select * from test1 where class like '%java%'; /* class 이름이 101로 끝나는 반의 모든 학생 조회하기 */ select * from test1 where class like '%101'; /* 학생의 이름에서 첫번째 문자가 s이고 두번째 문자가 0인 학생 중에서 딱 세자의 이름을 가진 학생을 모두 조회하라!*/ /* => %는 0자 이상을 의미하기 때문에 이 조건에 맞지 않다.*/ select * from test1 where name like 's0%'; /* => _는 딱 1자를 의미한다.*/ select * from test1 where name like 's0_'; |
### 날짜 다루기
- 날짜 함수와 문자열 함수를 사용하여 날짜 값을 다루는 방법.
| create table test1 ( no int not null, title varchar(200) not null, content text, regdt datetime not null ); alter table test1 add constraint primary key (no), modify column no int not null auto_increment; insert into test1(title, regdt) values('aaaa', '2022-01-27'); insert into test1(title, regdt) values('bbbb', '2022-2-2'); |
| - 날짜 값 비교하기 /* 특정 날짜의 게시글 찾기 */ select * from test1 where regdt = '2022-6-17'; /* 특정 기간의 게시글 조회 */ select * from test1 where regdt between '2022-11-1' and '2022-12-31'; select * from test1 where regdt >= '2022-11-1' and regdt <= '2022-12-31'; |
/* 현재 날짜 및 시간 알아내기 */ : select now();
/* 현재 날짜 알아내기 */ : select curdate(); 괄호빼도 됨
/* 현재 시간 알아내기 */ : select curtime(); 괄호빼도 됨
/* 주어진 날짜, 시간에서 날짜만 뽑거나 시간만 뽑기 */ : select regdt, date(regdt), time(regdt) from test1;
/* 특정 날짜에 시,분,초,일,월,년을 추가하거나 빼기*/
date_add(날짜데이터, interval 값 단위); select date_add(now(), interval 11 day);
date_sub(날짜데이터, interval 값 단위); select date_sub(now(), interval 11 day);
/* 두 날짜 사이의 간격을 알아내기 */
datediff(날짜1, 날짜2); select datediff(curdate(), '2023-2-10');
/* 날짜에서 특정 형식으로 값을 추출하기 */
date_format(날짜, 형식)
select regdt, date_format(regdt, '%m/%e/%Y') from test1; /* 09/7/2022 */
select now(), date_format(now(), '%Y-%m-%d');
%a : 요일약자
%w : 요일을 숫자로 (일요일이 1) %W : 요일
%M : July / %m : 07(월)
%p : AM / PM
%h: 시간 , %H: 24기준 시간
%i: 분, %s: 초

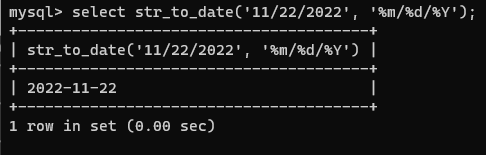
/* 문자열을 날짜 값으로 바꾸기 */
select str_to_date('11/22/2022', '%m/%d/%Y');
select str_to_date('2022.2.12', '%Y.%m.%d');
/* 날짜 값을 저장할 때 기본 형식은 yyyy-MM-dd이다. */
insert into test1 (title, regdt) values('aaaa', '2022-11-22');
/* 다음 형식의 문자열을 날짜 값으로 지정할 수 없다.*/
insert into test1 (title, regdt) values('bbbb', '11/22/2022');
/* 특정 형식으로 입력된 날짜를 date 타입의 컬럼 값으로 변환하면 입력할 수 있다.*/
insert into test1 (title, regdt) values('bbbb', str_to_date('11/22/2022', '%m/%d/%Y'));
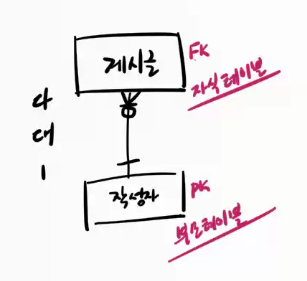
Foreign key
1. 중복 데이터를 효율적으로 관리하기 위해서 (별도 테이블에 분리 저장 => 두 데이터 간 PK로 관계 설정)
2. 가변 데이터를 효율적으로 관리하기 위해서 (별도 테이블에 분리 저장 => 두 데이터 간 PK로 관계 설정)
## 용어 정리
- test1 처럼 다른 테이블에 의해 참조되는 테이블을 '부모 테이블'이라 부른다.
- test2 처럼 다른 테이블의 데이터를 참조하는 테이블을 '자식 테이블'이라 부른다.
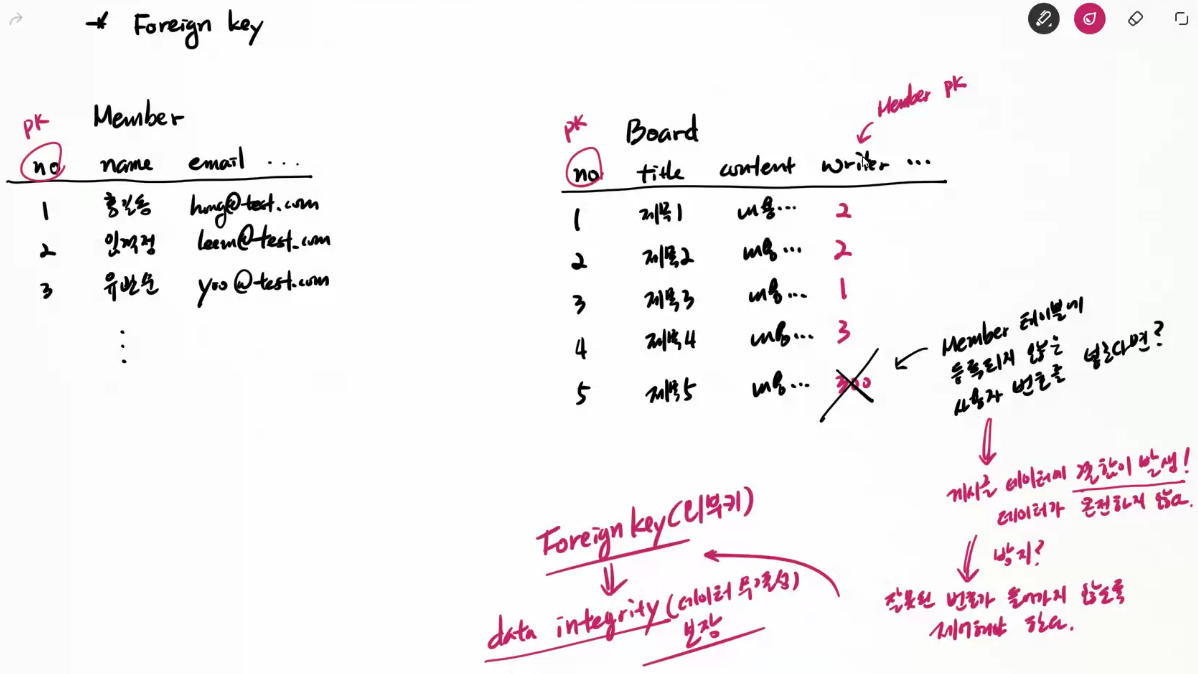
Foreign key 등장 배경 1
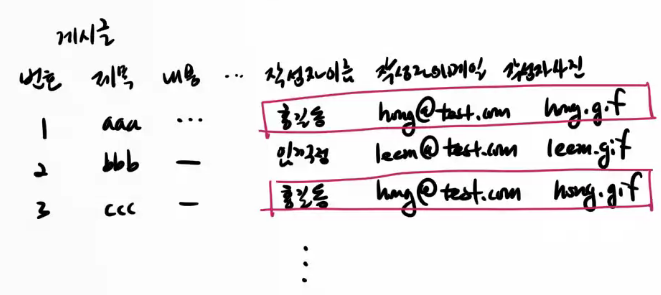
1. 메모리 낭비
2. 작성자 정보 변경시
- 관련된 데이터 모두 변경 = > 유지보수가 번거롭다.
- 만약 일부 게시글의 작성자 정보가 변경되지 않는다면 => 잘못된 작성자 정보를 갖고있다. = > 데이터 결함 발생
해결하기 위해: 중복 데이터를 별도로 유지해야 ,,, 됨 !
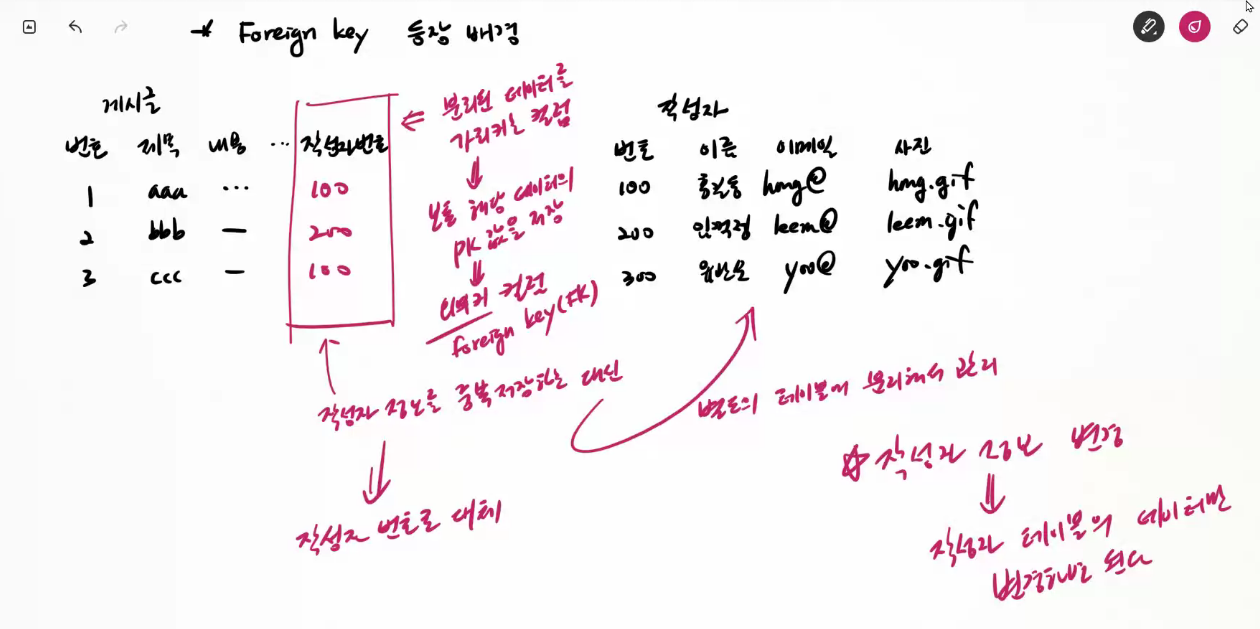
Foreign key 등장 배경 2 - 중복 컬럼 (가변 수의 데이터)

1. 게시글마다 첨부 파일의 갯수가 다르다.
2. 첨부 파일이 없는 경우 -> 컬럼 낭비
3. 첨부 파일이 많은 경우 -> 모두 저장할 수 없다.
해결책: 첨부파일을 별도 테이블로 분리해서 저장해야함.
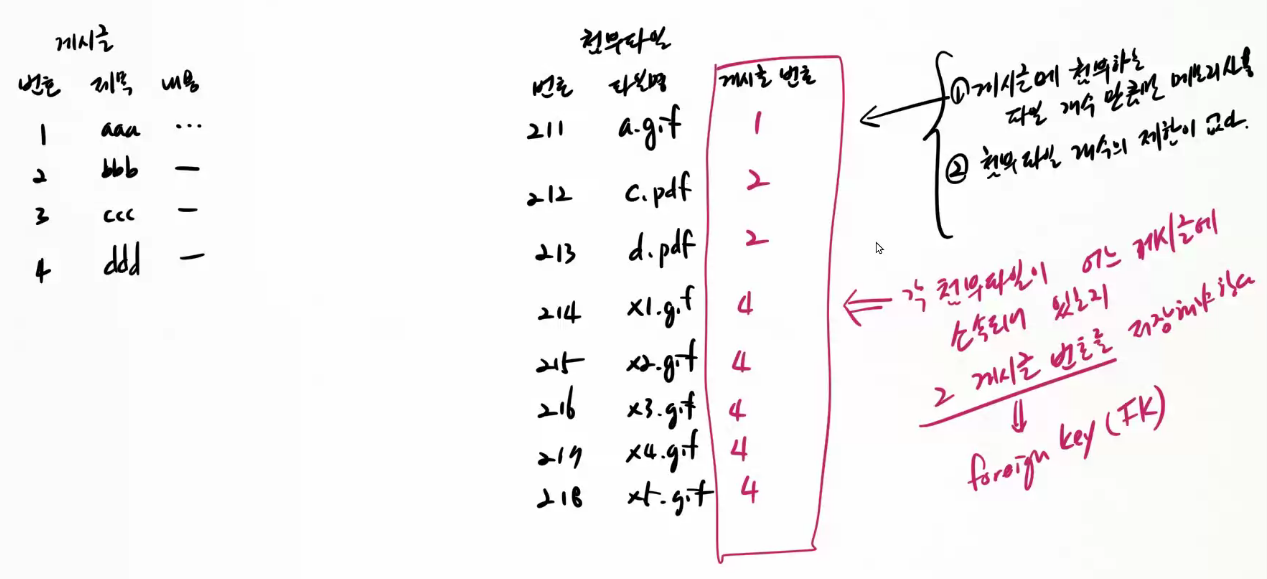
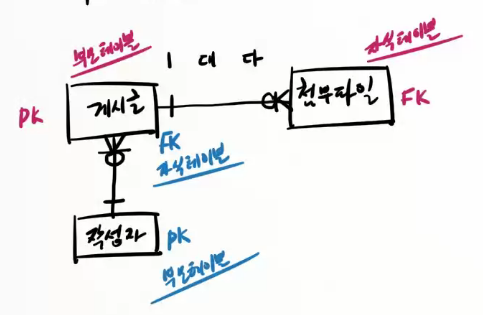
| ## FK(foreign key) 제약 조건 설정 - 다른 테이블의 데이터와 연관된 데이터를 저장할 때 무효한 데이터가 입력되지 않도록 제어하는 문법이다. - 다른 테이블의 데이터가 참조하는 데이터를 임의의 지우지 못하도록 제어하는 문법이다. - 그래서 데이터의 무결성(data integrity; 결함이 없는 상태)을 유지하게 도와주는 문법이다. 다른 테이블의 PK를 참조하는 컬럼으로 선언한다. alter table 테이블명 add constraint 제약조건이름 foreign key (컬럼명) references 테이블명(컬럼명); |
| /* fk 컬럼을 설정하기 전에 무효한 데이터를 삭제해야 한다. */ alter table test2 add constraint test2_bno_fk foreign key (bno) references test1(no); 위와 같이 test2 테이블에 FK 제약 조건을 건 다음에 데이터를 입력해보자! /* 5번, 10번 게시물은 존재하기 때문에 첨부파일 데이터를 입력할 수 있다.*/ insert into test2(filepath, bno) values('c:/download/d.gif', 5); insert into test2(filepath, bno) values('c:/download/e.gif', 5); insert into test2(filepath, bno) values('c:/download/f.gif', 10); /* 2번 게시물은 test2 테이블의 데이터들이 참조하지 않기 때문에 마음대로 지울 수 있다.*/ delete from test1 where no=2; ## 용어 정리 - test1 처럼 다른 테이블에 의해 참조되는 테이블을 '부모 테이블'이라 부른다. - test2 처럼 다른 테이블의 데이터를 참조하는 테이블을 '자식 테이블'이라 부른다. |
데이터 조작
1. DBMS Data 를 가공(옛날 방식) <= business logic (업무와 관련된 작업흐름)이 DBMS에 놓인다. (DBMS를 교체하면 많은 부분 변경 필요함)
| APP | SQL 요청 --> <-- 결과 응답 |
DBMS | 실행--> | SQL+DBMS 전용문법 |
| - client 쪽 프로그램은 간단하다 - SERVER 쪽 프로그램은 복잡하다 |
대부분의 로직을 DBMS에서 실행 DBMS에서 DATA를 가공 |
|||
| 1. DBMS에 종속적이다 - > DBMS 마다 유지보수 해야할 코드가 많다. 2. 데이터 가공을 DBMS에서 처리 -> 서버에 부하가 가중된다, client측 프로그램이 단순하다(= client 측 프로그램에 역량이 부족할 경우 주로 선택하는 방식) |
||||
2. App에서 Data 가공
| "Buniness Logic" APP |
SQL 요청 --> <-- 결과 응답 |
DBMS | 실행--> | SQL |
| client 측에서 데이터를 가공한다. => client의 프로그램이 복잡하다. => 업무가 변경될 때 DBMS의 영향을 받지 않고 유지보수할 수 있다. |
DBMS에서는 단순히 데이터를 찾아 리턴한다. => DBMS를 교체하더라도, 업무가 변경되더라도 SQL코드가 많이 변경되지 않는다. => DBMS 유지보수가 쉽다. DBMS 교체가 쉽다. |
|||
3. 데이터 가공을 어디에서 ?
| APP | SQL 요청-> <-결과응답 |
DBMS | 실행-> | SQL |
| UI변경, 업무 변경에 영향을 받는 데이터 인 경우 | UI와 관련없는 데이터인 경우, 업무로직에 영향을 받지 않는 경우 | |||
'[네이버클라우드] 클라우드 기반의 개발자 과정 7기 > 웹프로그래밍' 카테고리의 다른 글
| [NC7기-62일차(7월21일)] - 웹프로그래밍 43일차 (1) | 2023.07.21 |
|---|---|
| [NC7기-61일차(7월20일)] - 웹프로그래밍 42일차 (0) | 2023.07.20 |
| [NC7기-59일차(7월18일)] - 웹프로그래밍 40일차 (0) | 2023.07.18 |
| [NC7기-58일차(7월17일)] - 웹프로그래밍 39일차 (0) | 2023.07.17 |
| [NC7기-57일차(7월14일)] - 웹프로그래밍 38일차 (0) | 2023.07.14 |