DBMS : Database(data를 저장한 파일) 를 관리하는 시스템
Database Management System
ex) Oracle(Oracle), MS-SQL(MS), MySQL(Oracle), DB2(IBM), Tibero(Tmax), Cubrid, Altibase, MariaDB(MySQL호환), PostgreSQL
Database
데이터베이스는 전자적으로 저장되고 체계적이고 구조화된 데이터 집합.
단어, 숫자, 이미지, 비디오 및 파일을 포함한 모든 유형의 데이터가 포함
DBMS (데이터베이스 관리 시스템) 라는 소프트웨어에 의해 제어됨.
컴퓨터 시스템에서 데이터베이스라는 단어는 모든 DBMS, 데이터베이스 시스템 또는 데이터베이스와 관련된 응용 프로그램을 나타낼 수도 있습니다.
특징 : 실시간 접근성, 동시 공유, 일관성, 무결성(온전함, 결함이 없다), 보안성(권한이 있는 사람이 접근)
엑셀(은 낮은 단계의 데이터베이스) -보완 -> 엑세스 -보완-> ms sql
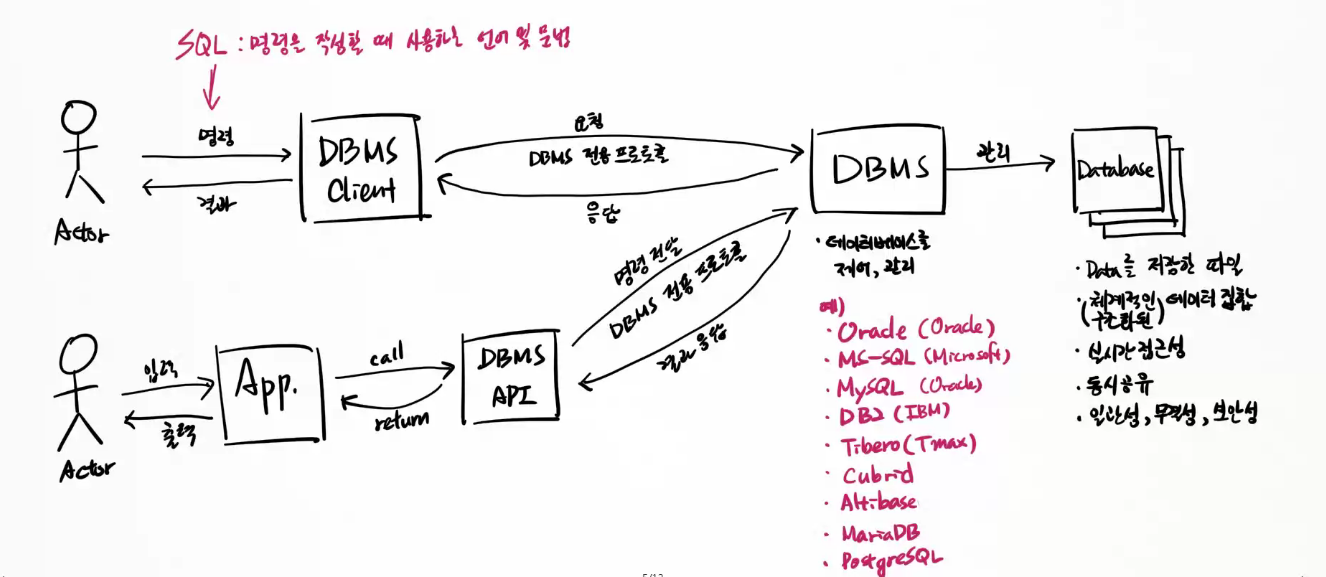
Actor가 DBMS Client에 명령내리고 (SQL:명령할 때 사용하는 언어 및 문법)
DBMS Client는 DBMS 전용 프로토콜로 DBMS에 작업 요청
Actor가 App에 입력하면
App이 DBMS API를 호출하고
API가 DBMS에 명령 전달(DBMS 전용 프로토콜을 통해)
*DB 프로그래밍 -1
| (DBMS API) = Native API = Vender API |
DBMS | ||||
| APP | call -> < - return |
Oracle API | 통신 <--> |
Oracle | |
| APP | call -> < - return |
MS-SQL API | 통신 <--> |
MS-SQL | |
| APP | call -> < - return |
My-SQL API | 통신 <--> |
My-SQL | |
| C/C++ DBMS마다 따로 프로그래밍 (단점) |
C/C++ Library DBMS 제조사에서 제공 API마다 사용법이 다르다 |
||||
=> ODBC API(규격) 만듬
*DB 프로그래밍 -2 : ODBC API 에 따라 구현된 driver
ODBC(Open DataBase Connectivity)는 마이크로소프트가 만든, 데이터베이스에 접근하기 위한 소프트웨어의 표준 규격
각 데이터베이스의 차이는 ODBC 드라이버에 흡수되기 때문에 사용자는 ODBC에 정해진 순서에 따라서 프로그램을 쓰면 접속처의 데이터베이스가 어떠한 데이터베이스 관리 시스템에 관리되고 있는지 의식할 필요 없이 접근할 수 있다.
| ODBC API 규격(spec)에 맞춰 구현 |
(DBMS API) = Native API = Vender API |
DBMS | ||||
| Oracle ODBC Driver |
call -> < - return |
Oracle API | 통신 <--> |
Oracle | ||
| MS-SQL ODBC Driver |
call -> < - return |
MS-SQL API | 통신 <--> |
MS-SQL | ||
| My-SQL ODBC Driver |
call -> < - return |
My-SQL API | 통신 <--> |
My-SQL | ||
| C/C++ , *.dll, * API 규격을 통일하여 APP을 DBMS 마다 따로 프로그래밍 할 필요가 없다! = DBMS에 독립적 |
||||||
*DB 프로그래밍 -3 : 자바 Type 1 Driver
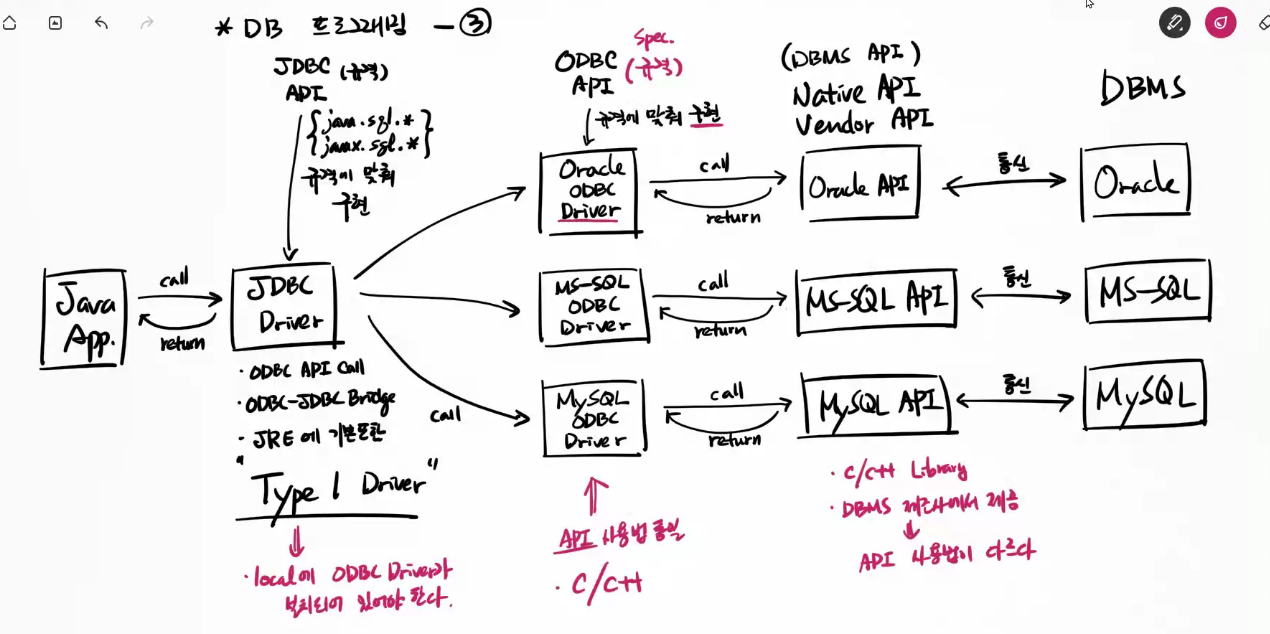
| JDBC API |
| {java.sql.* javax.sql.*} 규격에 맞춰 구현 |
| JDBC Driver |
| Java App |
call | JDBC Driver |
call | Oracle ODBC Driver | Oracle API | Oracle |
| call | MS-SQL ODBC Driver | MS-SQL API | MS-SQL | |||
| call | My-SQL ODBC Driver | My-SQL API | My-SQL | |||
| call | Excel ODBC Driver | Excel API | Excel & csv text file |
JDBC Driver: ODBC API CALL, ODBC JDBC Bridge, JRE에 기본 포함, 자바 라이브러리
"Type 1 Driver" => local에 ODBC Drvier가 설치 되어 있어야한다.
*DB 프로그래밍 -4 : 자바 Type 2 Driver
| JDBC API (규격)에 따라 구현 | (DBMS API) = Native API = Vender API |
DBMS | ||
| Java App |
Oracle JDBC Driver | call / return | Oracle API | Oracle |
| MS-SQL JDBC Driver | call / return | MS-SQL API | MS-SQL | |
| My-SQL JDBC Driver | call / return | My-SQL API | My-SQL | |
| APIT 사용법이 같기 때문에 Driver를 교체하더라도 App을 변경할 필요가 없다. |
* DBMS 제조사에서 제공, 별도의 다운로드 필요 * DBMS Native API 사용 - local에 DBMS Native API 설치 |
=> Type 2 Driver : Type 1보다 실행 속도 빠르다.
*DB 프로그래밍 -5 : 자바 Type 4 Driver
| JDBC API (규격)에 따라 구현 | DBMS | ||
| Java App |
Oracle JDBC Driver | 직접 서버와 통신 | Oracle |
| MS-SQL JDBC Driver | 직접 서버와 통신 | MS-SQL | |
| My-SQL JDBC Driver | 직접 서버와 통신 | My-SQL | |
| APIT 사용법이 같기 때문에 Driver를 교체하더라도 App을 변경할 필요가 없다. |
* DBMS 제조사에서 제공, 별도의 다운로드 필요 * DBMS 전용 프로토콜로 직접 통신 - local에 전용 API를 따로 설치할 필요가 없다. |
DBMS API 빠지고 Driver가 DBMS와 직접 통신 !
= > Type 4 Driver :C/C++ 함수를 호출하지 않기 때문에 드라이버가 100% 자바코드로만 되어있음 => "Pure Java"
OS마다 따로 설치할 필요가 없다, type 1, type2, type3는 OS마다 따로 설치 필요하다.
*DB 프로그래밍 -5 : 자바 Type 3 Driver
중계 서버용 JDBC Driver와 JDBC 중계 서버
| JDBC API (규격)에 따라 구현 | JDBC Driver | DBMS | ||
| Java App |
중계 서버용 JDBC Driver |
JDBC 중계 서버 |
Oracle JDBC Driver | Oracle |
| MS-SQL JDBC Driver | MS-SQL | |||
| My-SQL JDBC Driver | My-SQL | |||
| 중계마다 통신 => 실행속도 느리다 DBMS를 교체하더라도 JDBC Driver를 교체할 필요가 없다. "Type 3 Driver" *보통 상업용으로 유료 |
중간에서 중계해주는 S/W "Middleware" |
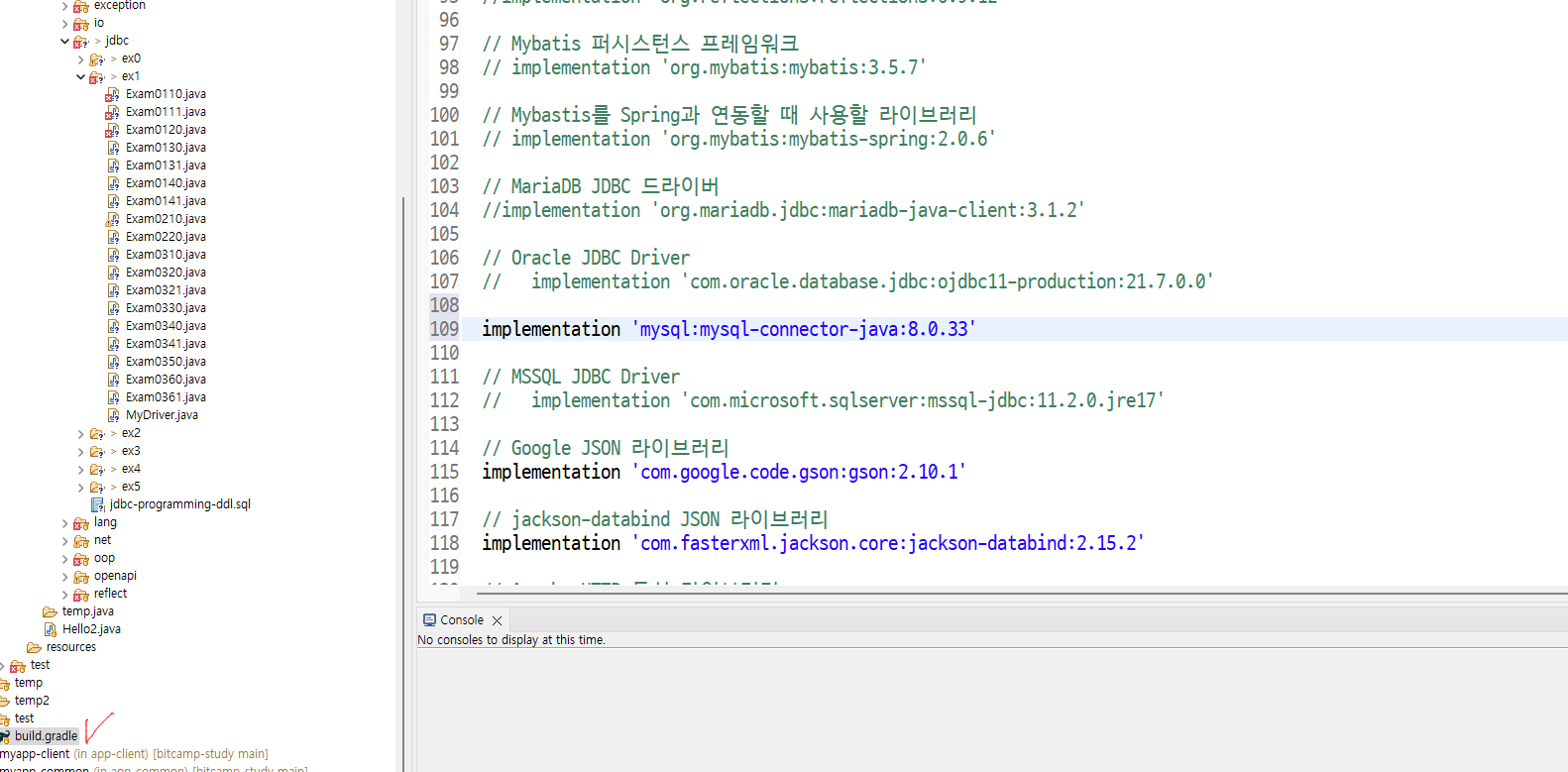
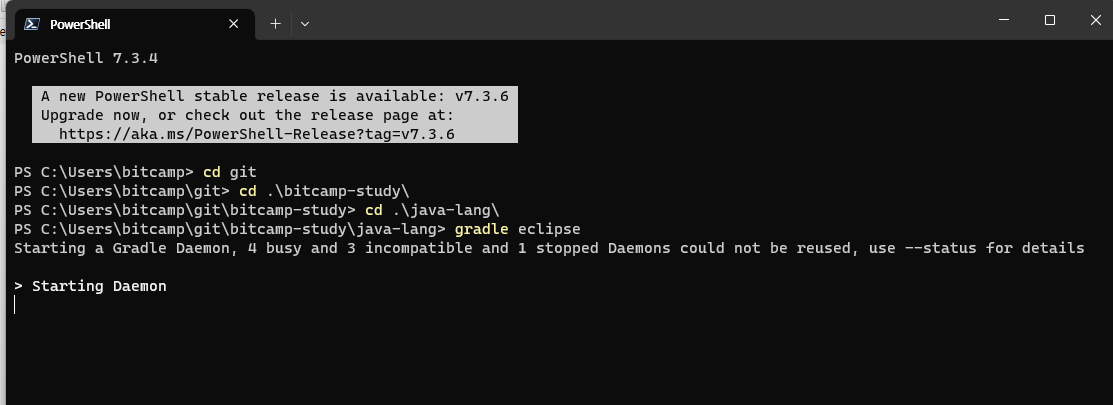
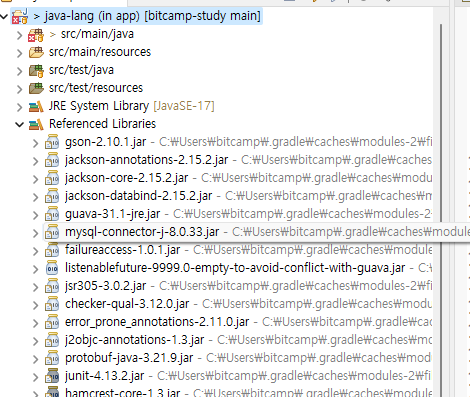
*MySQL 서버 기반 JDBC 프로그래밍
| Java App |
call (JDBC API) return |
MySQL JDBC Type4 Driver |
직접 통신 | MySQL 서버 |
| JDBC 드라이버 설치 필요 |
프로그램 준비

SQL 문법의 종류
| DDL(Data Definition Language) - 테이블 정의/변경/삭제 -뷰 -프로시저, 함수 정의/변경/삭제 등 |
ex) create table() alter table() drop table() |
| DML (Data Manipulation Language) - 데이터 입력/변경/삭제 등 |
insert / update/ delete |
| DQL (Data Query Language) -데이터 조회 등 |
select |
| DCL (Data Control Language) - 트랜젝션 제어 등 |
commit / rollback |
문자와 문자열을 구분하지 않고 ' '만 사용
DDL
DB 객체(테이블, 뷰, 프로시저, 함수, 트리거) 등을 생성, 변경, 삭제하는 SQL 명령
트리거: 특정 조건에서자동으로 호출되는 함수
| 데이터베이스 생성 create database 데이터베이스명 옵션들...; |
| 데이터베이스 삭제 drop database 데이터베이스명; |
| 데이터베이스 변경 alter database 데이터베이스명 옵션들...; |
| 모든 컬럼 값 출력 select * from test1(DB명); |
| #### not null 데이터를 입력하지 않으면 입력/변경 거절! create table test1( no int not null, name varchar(20) ); |
| #### 기본값 지정하기 입력 값을 생략하면 해당 컬럼에 지정된 기본값이 대신 입력된다. create table test1( no int not null, name varchar(20) default 'noname', age int default 20 ); 컬럼에 default 옵션이 있는 경우, - 컬럼 값을 생략하면 default 옵션으로 지정한 값이 사용된다. - 컬럼 값을 null로 지정하면 기본 값이 사용되지 않는다. |
| 예) create table test01 ( name varchar(50) not null, kor int not null, eng int not null, math int not null, sum int not null, aver float not null ); |
컬럼의 타입
| #### int - 4바이트 크기의 정수 값 저장. 소수점 이하 반올림하고 짜름 - 기타 tinyint(1바이트), smallint(2바이트), mediumint(3바이트), bigint(8바이트) |
| #### float - 부동소수점 저장 |
| #### numeric = decimal - 전체 자릿수와 소수점 이하의 자릿수를 정밀하게 지정할 수 있다. - numeric(n,e) : 전체 n 자릿수 중에서 소수점은 e 자릿수다. - 예) numeric(10,2) : 12345678.12 //소수점 2자를 초과한 값은 반올림 - numeric : numeric(10, 0) 과 같다. |
| #### char(n) - 최대 n개의 문자를 저장. - 0 <= n <= 255 - 고정 크기를 갖는다. - 한 문자를 저장하더라도 n자를 저장할 크기를 사용한다. - 메모리 크기가 고정되어서 검색할 때 빠르다. 1자를 저장하나 2자, 255자를 저장하나 지정한 크기만큼의 크기. |
| #### varchar(n) - 최대 n개의 문자를 저장. (바이트 갯수가 아님, 그냥 문자의 갯수) - 0 ~ 65535 바이트 크기를 갖는다. - n 값은 문자집합에 따라 최대 값이 다르다. - 한 문자에 1바이트를 사용하는 ISO-8859-n 문자집한인 경우 최대 65535 이다. - 그러나 UTF-8로 지정된 경우는, n은 최대 21844까지 지정할 수 있다. - 가변 크기를 갖는다. - 한 문자를 저장하면 한 문자 만큼 크기의 메모리를 차지한다. - 메모리 크기가 가변적이라서 데이터 위치를 찾을 때 시간이 오래 걸린다. 그래서 검색할 때 위치를 계산해야 하기 때문에 검색 시 느리다. |
| select * from test1 where c1='abc'; mysql은 고정크기 컬럼이더라도 빈자리를 무시하고 데이터를 찾는다. |
| #### text(65535), mediumtext(약 1.6MB), longtext(약 4GB) - 긴 텍스트를 저장할 때 사용하는 컬럼 타입이다. - 오라클의 경우 long 타입과 CLOB(character large object) 타입이 있다. |
|
| #### date - 날짜 정보를 저장할 때 사용한다. - 년,월,일 정보를 저장한다. - 오라클의 경우 날짜 뿐만 아니라 시간 정보도 저장한다. insert into test1(c1) values('2022-02-21'); |
다른 타입을 넣으면 맞는것만 저장되고 버려짐. 넣을 거 없으면 오류뜸 |
| #### time - 시간 정보를 저장할 때 사용한다. - 시, 분, 초 정보를 저장한다. insert into test1(c2) values('16:12:35'); |
|
| #### datetime - 날짜와 시간 정보를 함께 저장할 때 사용한다. insert into test1(c3) values('2022-2-21 16:5:3'); |
|
| #### boolean - 보통 true, false / 정수 1 또는 0 / Y 또는 N으로 표현하기도 한다. - 저장될 땐 1과 0으로 저장됨 - 실제 컬럼을 생성할 때 tinyint(1) 로 설정한다. create table test1( c1 char(1), c2 int, c3 boolean ); |
|
key column : 데이터를 구분할 때 사용하는 값
key(데이터를 구분하는 식별자, 한 개 이상의 컬)
컬럼 - name, email, jumin, id, pwd, tel, postno, basic_addr, gender
key: email, jumin, id, tel, (name, postno), (name, tel), (tel, detail_addr), (id, tel, gender)
candidate key (후보키 = 최소키) : key 들 중 최소 항목으로 줄인 키 : email, jumin, id, tel
=> 이미 한 개짜리 key가 있어서 두 개짜린 안 줄임
primary key:( DB Admin)가 후보키중에서 주 식별자로 선택한 키 : id
나머지 키: alternative key: email,, tel // 한 번 값을 입력하면 변경하지 않고 key를 주키(pk(로 선정한다. . pk는 변경할 수 없기 때문이다 key이기 때문에 중복 되어서는 안됨.
인공키( altificial key)
컬럼: title, contents,view-count;writer, creadAdd-dd;
게시글 에디터를 구형할 대 사용할 칼럼?
-> pk로 사용할 적절한 컬럼이 없을 경우 임의의 컬ㄻ 추가하여 pk 컬럼으로 지정한다.
#### primary key
- 테이블의 데이터를 구분할 때 사용하는 컬럼들이다.
- 줄여서 PK라고 표시한다.
- PK 컬럼을 지정하지 않으면 데이터가 중복될 수 있다.
PK는 기본이 not null
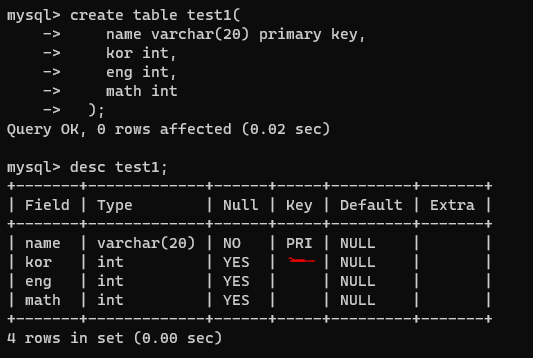
두 개 이상의 컬럼을 묶어서 pk로 선언하고 싶다면,,
constraint 제약조건이름 primary key (컬럼명, 컬럼명, ...)
| create table test1( name varchar(20), age int, kor int, eng int, math int, constraint test1_pk primary key(name, age) ); |
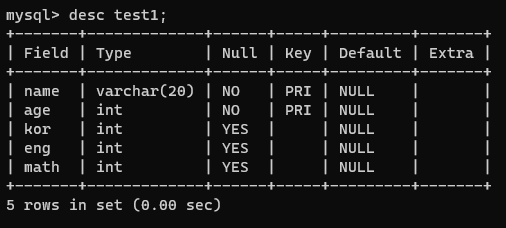 |
여러 개의 컬럼을 묶어서 pk로 사용하면 불편하기 때문에 '학번'과 같이 임의 값을 저장하는 컬럼을 만들어 pk로 사용한다!
하지만 pk는 아니지만 pk처럼 중복되어서는 안되는 컬럼을 지정할때 unique 사용
| create table test1( no int primary key, name varchar(20), age int, kor int, eng int, math int, constraint test1_uk unique (name, age) ); |
create table test1( no int, name varchar(20), age int, kor int, eng int, math int, constraint primary key(no), constraint test1_uk unique (name, age) ); |
| create table test1( no int, name varchar(20), age int, kor int, eng int, math int ); alter table test1 add constraint test1_pk primary key (no); alter table test1 add constraint test1_uk unique (name, age); |
<= 테이블 생성 후 수정(alter) |
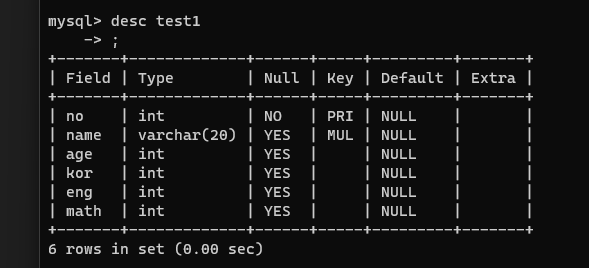 |
|
index
- 검색 조건으로 사용되는 컬럼인 경우 따로 정렬해 두면 데이터를 찾을 때 빨리 찾을 수 있다.
- 특정 컬럼의 값을 A-Z 또는 Z-A로 정렬시키는 문법이 인덱스이다.
- DBMS는 해당 컬럼의 값으로 정렬한 데이터 정보를 별도의 파일로 생성한다.
fulltext index test1_name_idx (name)
select * from test1 where name = 'bbb';
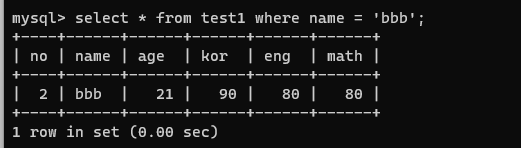
- name 컬럼은 인덱스 컬럼으로 지정되었기 때문에
DBMS는 데이터를 추가하거나 삭제할 때 name 컬럼의 색인표를 갱신한다.
- 단점, 이런 이유로 이름으로 검색할 때 찾기 속도는 빠르지만,
입력,변경,삭제 속도는 느리게 된다.
테이블 변경
| - 테이블에 컬럼 추가 alter table test1 add column no int; |
| - PK 컬럼 지정, UNIQUE 컬럼 지정, INDEX 컬럼 지정 alter table test1 add constraint test1_pk primary key (no), add constraint test1_uk unique (name, age), add fulltext index test1_name_idx (name); |
| - 컬럼에 옵션 추가 (컬럼 다 기재해야함) alter table test1 modify column name varchar(20) not null, modify column age int not null, modify column kor int not null, modify column eng int not null, modify column math int not null, modify column sum int not null, modify column aver float not null; |
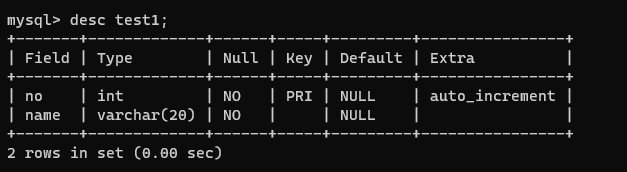
### 컬럼 값 자동 증가
- 숫자 타입의 PK 컬럼 또는 Unique 컬럼인 경우 값을 1씩 자동 증가시킬 수 있다.
- 즉 데이터를 입력할 때 해당 컬럼의 값을 넣지 않아도 자동으로 증가된다.
- 단 삭제를 통해 중간에 비어있는 번호는 다시 채우지 않고, 즉 증가된 번호는 계속 앞으로 증가할 뿐이다.
alter table test1
add constraint primary key (no); /* 일단 no를 pk로 지정한다.*/
alter table test1
modify column no int not null auto_increment;
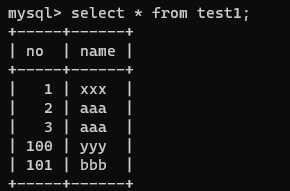
/* 값을 삭제하더라도 auto-increment는 계속 앞으로 증가한다.*/
delete from test1 where no=103;
insert into test1(name) values('eee'); /* no=104 */
## 뷰(view) -> 셀렉트문에 대한 단축키일뿐 ,, !
- 조회 결과를 테이블처럼 사용하는 문법
- select 문장이 복잡할 때 뷰로 정의해 놓고 사용하면 편리하다.
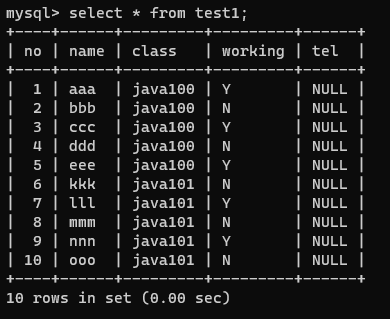 |
| - 직장인만 조회 select no, name, class from test1 where working = 'Y'; |
| - 직장인만 조회한 결과를 가상 테이블로 만들기 ==> 컬럼을 선택하는것: 프로젝션 create view worker as select no, name, class from test1 where working = 'Y'; 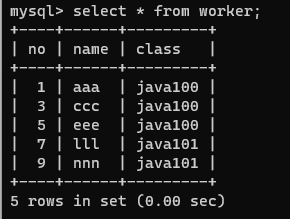 |
| select * from worker; ### 뷰 삭제 drop view worker; |
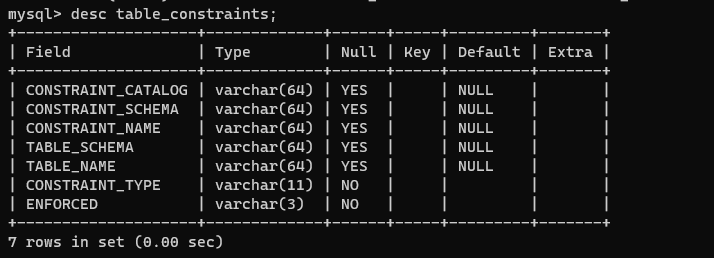
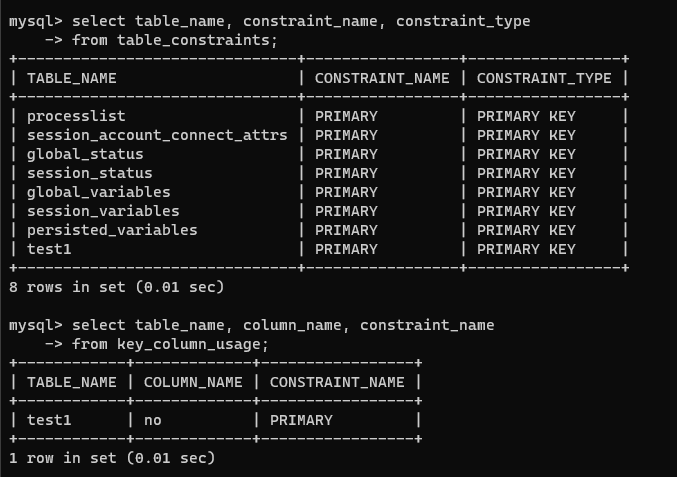
## 제약 조건 조회
1) 테이블의 제약 조건 조회
select table_name, constraint_name, constraint_type
from table_constraints;
2) 테이블의 키 컬럼 정보 조회
select table_name, column_name, constraint_name
from key_column_usage;
'[네이버클라우드] 클라우드 기반의 개발자 과정 7기 > 웹프로그래밍' 카테고리의 다른 글
| [NC7기-61일차(7월20일)] - 웹프로그래밍 42일차 (0) | 2023.07.20 |
|---|---|
| [NC7기-60일차(7월19일)] - 웹프로그래밍 41일차 (0) | 2023.07.19 |
| [NC7기-58일차(7월17일)] - 웹프로그래밍 39일차 (0) | 2023.07.17 |
| [NC7기-57일차(7월14일)] - 웹프로그래밍 38일차 (0) | 2023.07.14 |
| [NC7기-56일차(7월13일)] - 웹프로그래밍 37일차 (0) | 2023.07.13 |