파일 입출력 API 주요 클래스 (java.io 패키지)
| 1) 데이터 읽기 InputStream (추상 클래스) +-- FileInputStream : 바이트 단위로 읽기 (binary stream) Reader (추상 클래스) +-- FileReader : 문자 단위로 읽기 (character stream) |
2) 데이터 쓰기 OutputStream (추상 클래스) +-- FileOutputStream : 바이트 단위로 쓰기 (binary stream) Writer (추상 클래스) +-- FileWriter : 문자 단위로 쓰기 (character stream) |
| 1) 바이너리 파일 - character set(문자표) 규칙에 따라 작성한 파일이 아닌 파일. - 기본 텍스트 편집기(메모장, vi 에디터 등)로 편집할 수 없는 파일을 말한다. - 만약 텍스트 편집기로 변경한 후 저장하면, 파일 포맷이 깨지기 때문에 무효한 파일이 된다. - 예) .pdf, .ppt, .xls, .gif, .mp3, .jpg, .hwp, .mov, .avi, .exe, .lib 등 - 바이너리 파일을 편집하려면 해당 파일 포맷을 이해하는 전용 프로그램이 필요하다. |
2) 텍스트 파일 - 특정 character set(문자표) 규칙에 따라 작성한 파일. - 기본 텍스트 편집기(메모장, vi 에디터 등)로 편집할 수 있는 파일을 말한다. - 예) .txt, .csv, .html, .js, .css, .xml, .bat, .c, .py, .php, .docx, .pptx, .xlsx 등 - 텍스트 파일은 전용 에디터가 필요 없다. - 텍스트를 편집할 수 있는 에디터라면 편집 후 저장해도 유효하다. |
| 바이너리 데이터 읽고, 쓰기 - 읽고 쓸 때 중간에서 변환하는 것 없이 바이트 단위로 그대로 읽고 써야 한다. - InputStream/OutputStream 계열의 클래스를 사용하라. |
텍스트 데이터 읽고, 쓰기 - 읽고 쓸 때 중간에서 문자 코드표에 따라 변환하는 것이 필요하다. - Reader/Writer 계열의 클래스를 사용하라. |
io ex04 int & String 출력, 읽기
데이터 출력 : write
1) 파일로 데이터를 출력하는 객체를 준비한다.
- new FileOutputStream(파일경로)
- 지정된 경로에 해당 파일을 자동으로 생성한다.
- 기존에 같은 이름의 파일이 있으면 덮어쓴다.
FileOutputStream out = new FileOutputStream("temp/test3.data");
int money = 1_3456_7890; // = 0x080557d2
out.write(money); //항상 출력할 때는 맨 끝 1바이트만 출력한다.
out.close();

데이터 읽기 : read
1) 파일 데이터 읽기를 담당할 객체를 준비한다.
- new FileInputStream(파일경로)
- 해당 경로에 파일이 존재하지 않으면 예외가 발생한다.
FileInputStream in = new FileInputStream("temp/test3.data");
// Exam0110 실행하여 출력한 데이터를 read()로 읽는다.
// read()는 1바이트를 읽어 int 값으로 만든 후 리턴한다.
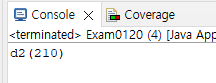
int value = in.read(); // 실제 리턴한 값은 0xD2이다.
in.close();
System.out.printf("%1$x(%1$d)\n", value);
int 메모리의 모든 바이트를 출력
int money = 1_3456_7890; // = 0x080557d2
// int 메모리의 모든 바이트를 출력하려면,
// 각 바이트를 맨 끝으로 이동한 후 write()로 출력한다.
// 왜?
// write()는 항상 변수의 마지막 1바이트만 출력하기 때문이다.
out.write(money >> 24); // 00000008|0557d2
out.write(money >> 16); // 00000805|57d2
out.write(money >> 8); // 00080557|d2
out.write(money); // 080557d2

FileInputStream in = new FileInputStream("temp/test3.data");
출력한 데이터를 read()로 읽기
// => 파일에서 4바이트를 읽어 4바이트 int 변수에 저장하라!
// => 읽은 바이트를 비트이동 연산자를 값을 이동 시킨 후 변수에 저장해야 한다.
// => 파일에 들어 있는 값 예: 080557d2
int value = in.read() << 24; // 00000008 => 08000000
value += (in.read() << 16); // 00000005 => + 00050000
value += (in.read() << 8); // 00000057 => + 00005700
value += in.read(); // 000000d2 => + 000000d2
//==========================================> 080557d2
in.close();
System.out.printf("%08x(%1$d)\n", value);

**long(8바이트) 값도 미뤄서 출력(write), 당겨서 읽기(read)
String 출력
String은 str.getBytes("UTF-8") 이용해서 ,,!
FileOutputStream out = new FileOutputStream("temp/test3.data");
String str = "AB가각간";
// str.getBytes(문자코드표)
// => 문자열을 지정한 문자코드표에 따라 인코딩하여 바이트 배열을 만든다.
// => str.getBytes("UTF-8")
// UCS2 문자 ===> UTF-8 문자
out.write(str.getBytes("UTF-8"));
out.close();

String 읽기
FileInputStream in = new FileInputStream("temp/test3.data");
byte[] buf = new byte[100];
int count = in.read(buf);
// 바이트 배열에 들어있는 값을 사용하여 String 인스턴스를 만든다.
// new String(바이트배열, 시작번호, 개수, 문자코드표)
// => 예) new String(buf, 0, 10, "UTF-8")
// buf 배열에서 0번부터 10개의 바이트를 꺼낸다.
// 그 바이트는 UTF-8 코드로 되어 있다.
// 이 UTF-8 코드 배열을 UCS2 문자 배열로 만들어 String 객체를 리턴한다.
String str = new String(buf, 0, count, "UTF-8");
in.close();
System.out.printf("%s\n", str);

ex06 버퍼 사용하기
입출력에 버퍼 적용하기
1. 버퍼 적용 전
데이터를 읽을 때 1바이트 씩 읽으면 오래걸림
왕창 받으면 훨 빨라짐

** HDD
파일시스템
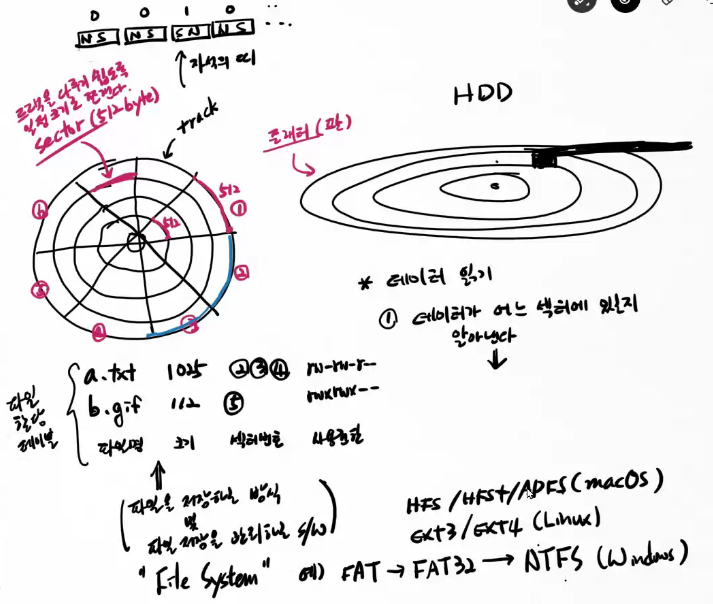
FAT(오래돼서 어떤 운영체제든 가능) FAT32 ( 파일 명 255자까지 가능, 맥 안 됨), NTFS (파일권한 설정가능, 맥 안됨)그래서 usb를 맥이랑 윈도우랑 공유 못 함. 하고 싶으면 FAT 방식으로 하기;
512바이트(물리섹터) 8개를 묶어서 (4k 4096) 1개의 논리섹터로 다룸
관리측면에서 섹터단위로 주소를 부여한다.

*데이터 읽기 = seek time + read time ( 2 & 3 반복)
1. 데이터가 어느 섹터에 있는지 파일 시스템을 통해 알아낸다.
2. 그 섹터가 있는 트랙으로 HDD 헤더를 이동시킨다. (오래걸림 0.0095초)
3. 트랙이 회전할 때 해당 섹터의 데이터를 읽는다. (얼마 안 걸림 0.00000015초)
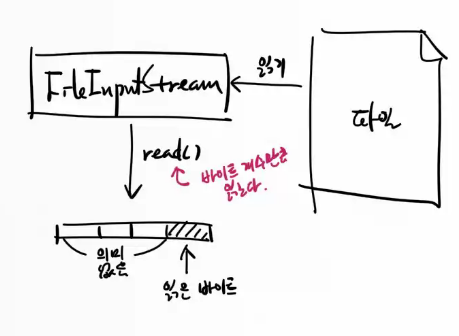
FileInputStream 의 read() : 바이트 개수만큼 읽는다.
HDD는 여러 프로그램이 같이 공유함.
파일을 읽는 그 순간 cache(임시 저장소)에 저장함 저장 안하면 그래서 헤더가 계속 움직여야하니까. cache에 저장하면 hdd 헤더가 움직이는 것보단 시간이 줄어드는 건 맞지만 seek 시간이 계속 드는 건 맞음.
BufferedFileInputStream
바이트 배열에서 데이터를 읽을 때 주의할 점 !

ex06 파일인풋스트림에 버퍼 추가해서 빨리 읽어오기 !
read 할때 8192 바이트 왕창 읽어오기! 데이터를 읽어들이는 시간보다 찾는 seek 시간이 훨씬 크기 때문에 seek 시간을 줄이는게 빨리 읽는 방법임
읽을 게 남았으면 buf에서 꺼내고, pos가 lenght랑 같으면(다 읽었다는 뜻),, 또 왕창 읽어오기
BufferedInputStream
package com.eomcs.io.ex06;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
public class MyFileInputStream extends FileInputStream{
byte[] buf = new byte[8192]; //8KB
int length; // 버퍼에 저장한 바이트 수
int pos; // 읽을 바이트의 인덱스
public MyFileInputStream(String name) throws FileNotFoundException{
super(name);
}
@Override
public int read() throws IOException {
if (pos >= length) { //버퍼의 데이터를 다 읽었다면,
length = this.read(buf); // 버퍼 크기만큼 파일에서 데이터를 읽어들인다.
if (length == -1) {
length = 0;
return -1;
}
pos = 0; //버퍼 시작부터 읽을 수 있도록 위치를 0으로 설정한다.
System.out.println(length + "8192 바이트 읽었음! ");
}
return buf[pos++] & 0x000000ff;
}
}
| BufferedOutputStream은 내부적으로 데이터를 버퍼에 모아두었다가, 버퍼가 가득 차거나 flush() 메서드가 호출될 때 버퍼의 내용을 출력 스트림으로 전송합니다. 따라서 flush() 메서드를 호출하면 버퍼에 남아있는 데이터가 모두 출력 스트림으로 전송되며, 버퍼는 비워집니다. |
|
// FileOutputStream
// - 파일 저장소에서 데이터를 출력하는 일을 한다. FileOutputStream out1 = new FileOutputStream("temp/members.data"); // FileOutputStream + BufferedOutputStream // - 버퍼로 출력한 다음에 버퍼가 모두 차면 한번에 출력한다. // - 출력 속도를 높이는 일을 한다. BufferedOutputStream out2 = new BufferedOutputStream(out1); // FileOutputStream + BufferedOutputStream + DataOutputStream // - 문자열이나 자바 기본 타입의 데이터를 좀 더 쉽게 출력하기 // - 그러나 안타깝게도 이런 식으로 기능을 확장할 수 없다. // - DataOutputStream 생성자에는 InputStream 객체만 넘겨줄 수 있다. // - 즉 DataOutputStream은 OutputStream 객체에만 연결할 수 있다. // - BufferedOutputStream은 OutputStream 의 자식이 아니기 때문에 DataOutputStream에 연결할 수 없다. DataOutputStream out3 = new DataOutputStream(out2); // 컴파일 오류! |
write 또한 ,, 버퍼 사용하면 빠름 !

버퍼가 넘 커지면
데이터 싱크타임이 넘 늘어남 ;
서버 프로그램을 수천명이 접속해서 쓰는건데 버퍼를 넘 크게 잡으면 한사람의 요청을 해결하는게 아니라 수천명의 요청을 해결해야하니까 넘 크면 안됨 ,,, 그래서 8K 16K정도 크기가 적절한 검증된 크기라고 들어서 씁니다...
Inversion of Control 제어의 역전 - 주입 , , ,
-Dependency Injection,의존 객체 주입
-Listener
30. 기능을 확장할 때 상속 대신 Decorator 패턴 적용
1. 상속을 이용한 기능확장의 문제점
| File Input Stream - 파일 데이터 읽기 byte, byte[] 읽을 때 사용 Primitive Type, String 읽기 불편 |
|
| Data Input Stream (File Input Stream 상속 받음) Primitive type, String 읽기 편해짐 바이트 단위로 읽기 때문에 대량의 데이터를 읽을 때 overhead(Data seek time) 발생 |
Buffered File Input Stream(File Input Stream 상속 받음) primitive type, String 의 데이터를 읽을 필요가 없을 경우에 사용할 클래스. 바이트 단위로 데이터를 읽을 때 읽기 성능을 개선할 목적 |
| Buffered Data Input Stream (Data Input Stream 상속 받음) 버퍼를 이용해서 읽기 성능 개선 |
* 상속은 중간 부모의 기능을 제거할 수 없고 다중 상속이 불가능하고, 별도의 클래스를 생성하여 기존 코드를 복사해와야한다, 그러면,,, 코드 중복이 발생함!!!! .
=> 상속의 한계 , ,!
2. Decorator 패턴 (GoF)
:장식품(decorator)처럼 기능을 덧붙이고 떼기 쉽게 할 수 있는 설계 구조
(Composite 패턴과 유사)

<<abstract>> InputStream 의 추상메서드: read()
Decorator
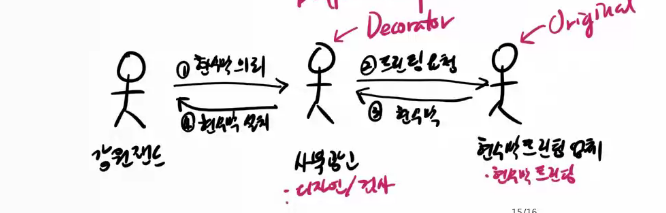
오리지널이 있고 데코레이터를 덧붙여줘야함.
Java Stream API 분류

'[네이버클라우드] 클라우드 기반의 개발자 과정 7기 > 웹프로그래밍' 카테고리의 다른 글
| [NC7기-48일차(7월3일)] - 웹프로그래밍 29일차 (0) | 2023.07.03 |
|---|---|
| [NC7기-47일차(6월30일)] - 웹프로그래밍 28일차 (0) | 2023.06.30 |
| [NC7기-45일차(6월28일)] - 웹프로그래밍 26일차 (0) | 2023.06.28 |
| gradle cleanEclipse (0) | 2023.06.28 |
| [NC7기-44일차(6월27일)] - 웹프로그래밍 25일차 -2 (0) | 2023.06.27 |